

PC | 인텔 Xe-HPG 마이크로 아키텍처, 인텔 아크(Intel Arc)
현재 PC 그래픽 시장은 PC 게이밍 유저가 꾸준하게 증가하는 추세이며 15억(1.5B) 이상의 PC 게이머가 게임을 즐기고 있고 라이브 스트림(Live Streams) 시청 시간은 88억(8.8B) 이상, 2020년 스팀(Steam) 기준 10000명 이상의 게임과 1300백만 이상의 게임 개발자들이 게임을 개발 중이다.
이와 함께 컴퓨팅이 요구되는 백신 개발과 서버 등 전문적인 처리를 위한 GPU 성능도 중요해지며 게임 콘솔과 PC 게이밍 등 GPU 활용 방향은 더욱 발전되고 있다. 그만큼 인텔의 데스크탑 및 서버 시장을 위한 그래픽 시장 진입은 당연한 수순이 될 수밖에 없으며 Xe 마이크로 아키텍처 기반의 Xe-HPG/ Xe-HPC는 인텔의 그래픽 시장 진출에 대한 의지를 보여준다. 인텔 그래픽의 데스크탑 및 서버 시장의 진입으로 AMD와 엔비디아(NVIDIA)의 2강 구도에도 많은 변화가 이루어질 것으로 예상된다.

인텔의 그래픽 시장 확장은 11세대 코어 프로세서를 발표하며 공개한 Xe 마이크로 아키텍처로 확인된다. Xe 마이크로 아키텍처는 Xe-LP로 내장 그래픽(iGPU) 시장을 우선 전환했다. Xe-LP는 기존 11세대 내장 그래픽(Gen 11)이 9세대 내장 그래픽(Gen 9) 대비 2배(2X)의 성능 향상이 이루어진 것과 같이 다시 2배의 향상으로 이어졌다. 이어 인텔은 내장 그래픽에 그치지 않고 8월 19일(현지시간) 인텔 아키텍처 데이 2021(Intel Architecture Day 2021)을 통해 외장 그래픽 시장을 위해 Xe-HPG/ Xe-HPC를 공개했다.
인텔 아키텍처 데이 2021을 통해 인텔은 새로운 두 개의 x86 코어 아키텍처와 인텔 쓰레드 디렉터 워크로드 스케줄러를 탑재한 인텔 최초의 퍼포먼스 하이브리드 아키텍처의 앨더레이크, 데이터센터용 차세대 인텔 제온 스케일러블 프로세서인 사파이어 래피즈, 인프라 처리 장치(IPU), 그래픽 아키텍처 제품군으로 Xe HPG와 Xe HPC 아키텍처, 알케미스트와 폰테배키오 시스템-온-칩(SoC) 등 다양한 기술을 발표했다.

Xe-HPG(Xe-High Performance Gaming)는 게이밍 및 창작 워크로드에 적합한 전문가 수준의 성능에 맞춰 확장되도록 설계된 새로운 외장 그래픽 마이크로아키텍처로 뛰어난 확장성과 컴퓨팅 효율을 제공하도록 설계 됐다. 함께 공개한 Xe-HPC(Xe-High Performance Computing)는 전문적인 분야를 위한 높은 컴퓨팅 성능과 확장성 및 효율을 제공한다.
이날 발표에서 인텔은 생산 전 단계에 있는 알케미스트 SoC에서 실행되는 마이크로아키텍처 세부 사항과 데모를 공개했으며 실제 게임플레이와 언리얼 엔진 5(Unreal Engine 5) 상태 테스트, 새로운 신경 기반 슈퍼 샘플링 기술인 Xe SS를 소개했다.

Xe HPG 마이크로 아키텍처는 TSMC의 N6(6nm FinFET) 공정으로 제조되며 컴퓨팅에 중점을 두고 프로그래밍이 가능하며 확장 가능한 새로운 Xe-코어(Xe-Core) 요소가 포함된다. 다이렉트X 12 얼티밋(DirectX 12 Ultimate)용으로 설계된 고정 기능을 갖춘 최대 8개의 렌더 슬라이스(Render Slices), 16개의 벡터 엔진(Vector engine)과 16개의 메트릭스 엔진(Matrix engeine, Xe Matrix eXtensions, 이하 XMX), 캐시 및 공유 로컬 메모리를 갖춘 새로운 Xe 코어, 다이렉트X 레이 트레이싱(DXR) 및 벌컨 레이 트레이싱(Vulkan Ray Tracing)을 지원하는 새로운 레이 트레이싱을 지원한다.


Xe HPG의 렌더링을 위한 Xe-코어를 조금 더 자세히 보면 벡터 엔진 1개 당 메트릭스 엔진(XMX) 1개를 대응하고 있다. Xe HPG는 1개에서 최대 8개의 렌더 슬라이스를 이용할 수 있으며 1개의 렌더 슬라이스에는 XMX를 포함한 4 Xe-Core를 이용하며 DX12 얼티밋 게이밍을 위해 고정 유닛으로는 지오메트리 파이프라인(Geometry Pipeline), 래스터 파이프라인(Rasterization Pipeline), 샘플러(Samplers) 32개, 픽셀 백엔드(Pixel Backends) 16개를 제공한다. 레이 트레이싱 유닛(Ray Tracing Units)은 4개로 레이 트레버셜(Ray Traversal), 바운딩 박스 언터섹션(Bounding Box Intersection), 트라이앵글 언터섹션(Tringle Intersection)을 포함한다. 그 외 글로벌 디스패치(Global Dispatch), 대용량 L2 캐쉬를 제공한다.

구성에 따라 1개의 렌더 슬라이스는 64개 벡터 및 매트릭스 엔진, 4개의 레이 트레이싱 유닛과 샘플러 32개, 픽셀 백엔드 16개를 이용할 수 있다. 8개의 렌더 슬라이스는 512개 벡터 및 매트릭스 엔진, 32개의 레이 트레이싱 유닛과 샘플러 256개, 픽셀 백엔드 128개를 이용할 수 있다.
이전 Xe-HPC의 GPU 타일(Tile)에서 512개 실행유닛(512EUs, 4096코어), 2타일 1024개 실행유닛으로 8192코어, 4타일은 2048개 실행유닛으로 16384 코어 구성으로 보면 Xe-HPG는 512개 실행 유닛으로 4096코어를 이용하고 라인업에 따라 다양한 구성이 가능해진다. 또 Xe-HP 단일 타일은 4K 60 HEVC 컨텐츠 10개의 개별 스트림을 트랜스코딩할 수 있는 성능으로 4타일은 40개의 다른 스트림을 트랜스코딩할 수 있으며 MCM GPU로 1.3GHz 클럭에서 FP32 42 TFLOPs 연산 성능을 제공하는 것으로 알려진 바 있다.


Xe-HPC는 16 Xe-코어와 L1 8MB 캐쉬, 16 레이 트레이싱 유닛, 1 하드웨어 컨텍스트(1 Hardware Context)로 구성되며 Xe HPC 스택(Stack)은 최대 4 슬라이스(Slice)로 64 Xe-코어와 64 레이 트레이싱 유닛, 4 하드웨어 컨텍스트(4 Hardware Context), L2 캐쉬, 4 HMB2e 컨트롤러, 1 미디어 엔진(Media Engine), 8 Xe-Links로 구성된다. 2 스택은 8 슬라이스로 128 Xe- 코어와 128 레이 트레이싱 유닛, 8 하드웨어 컨텍스트(8 Hardware Context), 8 HMB2e 컨트롤러, 2 미디어 엔진(2 Media Engines), 16 Xe-Links를 제공한다. Xe-코어 컴퓨팅 성능은 벡터 엔진(ops/clk)는 256 FP32, 256 FP64, 512 FP16 연상 성능, 매트릭스 엔진(ops/clk)은 2048 TF32, 4096 FP16, 4096 BF16, 8192 INT8(정수 연산) 성능을 각각 제공하는데 Xe-HPG의 Xe-코어는 전문적인 컴퓨팅 연산 성능 보다는 게이밍에 최적화된 만큼 이와 처리 성능 및 지원에 차이를 보일 수 있다.
Xe HPG의 Xe-코어는 Xe-HPC(Xe-High Performance Computing)을 타겟으로 하는 Xe-코어 구성과 차이를 보인다. Xe HPG의 Xe-코어는 256bit 16 벡터 엔진과 1024bit 16 매트릭스 엔진을 기반으로 구성하는데 반해 Xe-HPC의 Xe-코어는 512bit 8 벡터 엔진과 4096bit 매트릭스 엔진으로 구성된다. Xe-HPC는 Xe-HPG 대비 각각 절반인 8개의 벡터 및 매트릭스 엔진을 제공한다. 이는 Xe-HPG가 게이밍을 위해 벡터와 매트릭스 엔진을 코어 당 늘려 연산 효율을 높인 구조인 반면 Xe-HPC는 고성능 컴퓨팅으로 높은 컴퓨팅 연산을 필요로 하는 전문적인 분야에의 최적화를 위해 더 넓은 대여폭을 제공하는 백터와 매트릭스 엔진으로 구성됐다. Xe-HPC는 로드/스토어(Load/ Store) 512B/CLK, 캐쉬 L1$/ SLM(512KB), I$로 구성되는데 Xe-HPC는 게이밍에 보다 최적화된 캐쉬 구조를 제공할 것으로 예상된다.
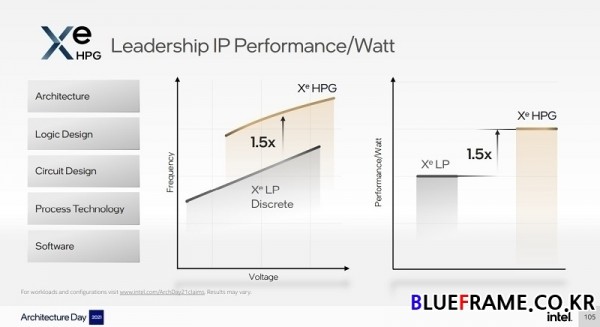
Xe HPG의 아키텍처와 로직 설계, 회로 설계, 공정 기술 및 소프트웨어 최적화 조합을 통한 Xe LP 마이크로 아키텍처 대비 1.5배 클럭스피드 증가 및 1.5배 와트당 성능 향상이 이루어졌다.
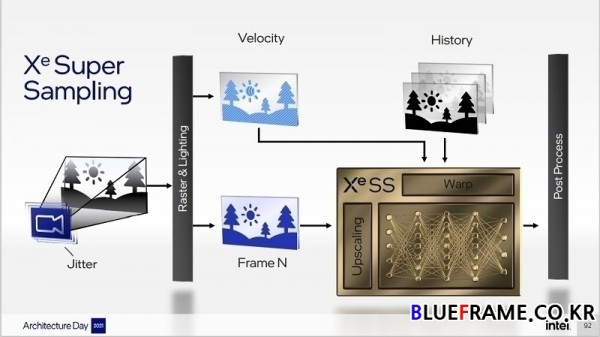

Xe SS(Xe Super Sampling)은 알케미스트가 내장한 XMX AI 가속 기술의 이점을 통해 고성능 및 하이파이(high-fidelity) 시각화가 가능한 새로운 업스케일링 기술이다. 딥러닝 기술을 활용해 기본 고해상도 렌더링 품질에 매우 가까운 이미지를 합성한다. Xe SS를 사용하면 낮은 품질의 설정이나 낮은 해상도에서만 플레이 가능한 게임도 고품질 및 고해상도에서 매끄럽게 구동되는 것을 목표로 한다.




Xe SS는 모션 보정된 이전 프레임 뿐 아니라 인접 픽셀에서 하위 픽셀 세부 정보를 재구성해 작동한다. 재구성은 높은 성능과 우수한 품질을 전달하도록 훈련된 신경 네트워크에 의해 수행된다. Xe SS는 DP4a 명령어 세트를 활용해 통합 그래픽을 포함한 광범위한 하드웨어에서 AI 기반 슈퍼 샘플링을 제공한다. 몇몇 초기 게임 개발자들이 Xe SS 개발에 참여하고 있으며 ISV용 초기 XMX 버전의 SDK는 이번 달에 가용할 예정이다. DP4a 버전은 올해 말 출시 예정이다.
인텔 Xe SS 기술은 엔비디아(NVIDA) 지포스 RTX 20/ 30 시리즈가 전용 하드웨어인 텐서 코어(Tensor Cores)를 통해 템포럴 업샘플링과 머신러닝을 통해 DLSS 2.0을 구현하는 것과 유사하다. 텐서 코어에 대비되는 전용 매트릭스 엔진(XMX)을 이용해 빠른 업스케일링이 가능하며 범용적인 DP4a 명령어로 AMD와 내장 그래픽(iGPU) 등 다른 플랫폼과 시스템에서도 그래픽 품질과 성능 향상이 가능해진다.
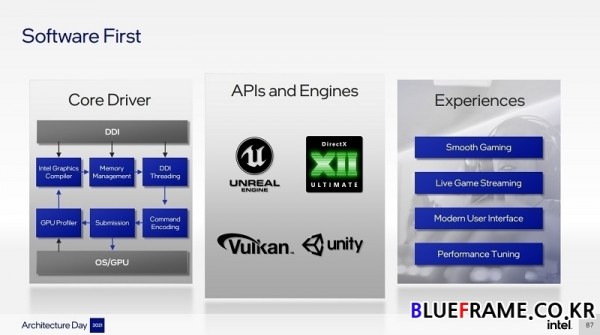

인텔의 그래픽에 관한 노력의 핵심은 소프트웨어를 우선하는 접근 방식이다. 원API(OneAPI)를 통해 서드파티와 전문 분야 워크로드, CPU와 GPU 구분 없이 최적화를 통해 성능을 향상한다. Xe 아키텍처를 개발자와 긴밀한 협업으로 설계하여 업계 표준에 부합하도록 유도하며 첫 고성능 게이밍 GPU는 하나의 통합된 코드베이스에서 내장 및 외장 그래픽 제품을 다루는 드라이버 설계를 통해 성능과 품질에 우선순위를 부여한다. 인텔은 핵심 그래픽 드라이버 구성요소, 특히 메모리 관리자 및 컴파일러의 아키텍처를 재구성하여 CPU 중심인 게임 타이틀의 스루풋을 15%(최대 80%) 개선하고 게임 로드 시간을 최대 25% 향상한다.

한편 Xe HPG 마이크로아키텍처는 알케미스트(Alchemist) 시스템-온-칩(SoC) 제품군을 강화하며 클라이언트 그래픽 로드맵에는 알케미스트(이전의 DG2), 배틀메이지(Battle Mage), 셀레스티얼(Celestial) 및 드루이드(Druid) SoC가 포함된다. 인텔 아크 브랜드로 2022년 1분기에 첫 관련 제품이 출시된다.
인텔, intel, 인텔 아키텍처 데이 2021, Intel Architecture Day 2021, 데스크탑, 게이밍, Xe, 마이크로 아키텍처, Xe HPG, Xe-HPG, Xe-Core, Xe-코어, 알케미스트, Alchemiest, TSMC, N6, 제조 공정, 다이렉트X 12 얼티밋, DirectX 12 Ultimate, 시스템 온 칩, SoC, DG2, 배틀 메이지, Battle Mage, 셀레스티얼, Celestial, 드루이드, Druid, 인텔 아크, Intel Arc, Arc, 아크, 202










