

IT | 엔비디아 H100 GPU, MLPerf 벤치마크서 생성형 AI 표준 설정
엔비디아(www.nvidia.co.kr, CEO 젠슨 황)가 MLPerf 벤치마크에서 엔비디아 H100 텐서 코어 GPU(NVIDIA H100 Tensor Core GPU)가 생성형 AI를 구동하는 대규모 언어 모델(LLM)에서 최고의 AI 성능을 제공한다고 밝혔다.
최신 MLPerf 트레이닝 벤치마크에서 H100 GPU는 8개의 테스트 모두에서 신기록을 세웠으며, 생성형 Al를 위한 새로운 MLPerf 테스트에서 탁월한 성능을 발휘했다. 이러한 우수성은 개별 가속기와 대규모 서버에서 모두 제공된다.

스타트업 인플렉션(Inflection) AI가 공동 개발하고 GPU 가속 워크로드 전문 클라우드 서비스 제공업체인 코어위브(CoreWeave)가 운영하는 3,584개의 H100 GPU로 구성된 상용 클러스터에서 이 시스템은 11분 이내에 대규모 GPT-3트레이닝 벤치마크를 달성했다.
코어위브 공동설립자 겸 CTO 브라이언 벤투로(Brian Venturo)는 "우리 고객들은 오늘날 빠르고 지연 시간이 짧은 인피니밴드 네트워크에서 수천 개의 H100 GPU를 통해 최첨단 생성형 AI 및 LLM을 대규모로 구축하고 있다. 엔비디아와 공동으로 제출한 MLPerf는 우리 고객들이 누리고 있는 뛰어난 성능을 명확하게 보여준다"고 말했다.
현존하는 최고의 성능
인플렉션 AI는 이러한 성능을 활용해 최초의 개인용 AI인 Pi(Personal Intelligence)의 기반이 되는 고급 LLM을 구축했다. 인플렉션은 사용자가 간단하고 자연스러운 방식으로 상호 작용할 수 있는 개인용 AI를 개발하는 AI 스튜디오 역할을 하게 된다.
인플렉션 AI CEO 무스타파 설리만(Mustafa Suleyman)은 “코어위브의 강력한 H100 GPU 네트워크에서 훈련된 최첨단 대규모 언어 모델을 기반으로 누구나 개인용 AI의 힘을 경험할 수 있다"고 말했다.
2022년 초 딥마인드(DeepMind)의 무스타파와 카렌 사이모니언(Karén Simonyan), 리드 호프먼(Reid Hoffman)이 공동 설립한 인플렉션 AI는 코어위브와 협력해 엔비디아 GPU를 사용하는 세계 최대 규모의 컴퓨팅 클러스터 중 하나를 구축하는 것을 목표로 한다.
경쟁 제품 대비 뛰어난 성능
이러한 사용자 경험은 이번 MLPerf 벤치마크에서 입증된 성능을 반영한다.
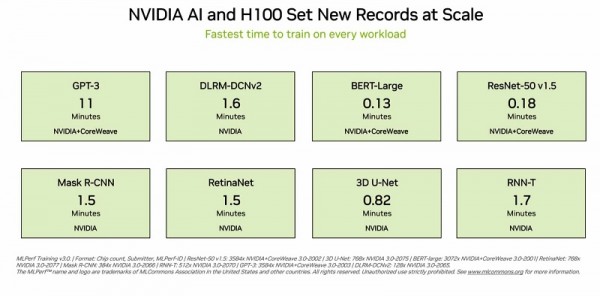
H100 GPU는 대규모 언어 모델, 추천자, 컴퓨터 비전, 의학 이미지 및 음성 인식을 포함한 모든 벤치마크에서 최고의 성능을 선보였다. H100 GPU는 8개의 테스트를 모두 실행한 유일한 칩으로, 엔비디아 AI 플랫폼의 뛰어난 활용성을 입증했다.
대규모 운영에서도 유지되는 우수성
트레이닝은 일반적으로 많은 GPU가 함께 작동해 대규모로 실행되는 작업이다. 모든 MLPerf 테스트에서 H100 GPU는 AI 훈련을 위한 새로운 대규모 성능을 기록했다.
H100 GPU 서버의 전체 스택에 걸친 최적화를 통해 제출물이 수백 대에서 수천 대의 H100 GPU로 확장됐다. 이에 따라 까다로운 LLM 테스트에서도 거의 선형에 가까운 성능 확장이 가능했다.

또한 코어위브는 클라우드에서 로컬 데이터센터에서 실행되는 AI 슈퍼컴퓨터와 유사한 성능을 제공했다. 이는 코어위브가 사용하는 엔비디아 퀀텀 인피니밴드(Quantum InfiniBand) 네트워킹의 저지연 네트워킹을 입증하는 결과다.
이번 라운드에서 MLPerf는 추천 시스템에 대한 벤치마크도 업데이트했다.
새로운 테스트는 클라우드 서비스 제공 업체가 직면한 과제를 보다 잘 반영하기 위해 더 큰 데이터 세트와 최신의 AI 모델을 사용했다. 엔비디아는 강화된 벤치마크에 대해 결과를 내놓은 유일한 기업이다.
확장되는 엔비디아 AI 에코시스템
이번 라운드에는 약 12개의 기업이 엔비디아 플랫폼에 대한 결과를 제출했다. 이들의 연구는 엔비디아 AI가 업계에서 가장 광범위한 머신 러닝 에코시스템의 지원을 받고 있음을 보여준다.
에이수스(ASUS), 델 테크놀로지스(Dell Technologies), 기가바이트(GIGABYTE), 레노버(Lenovo), QCT를 비롯한 주요 시스템 제조업체에서 제출한 30개 이상의 출품작이 H100 GPU에서 실행됐다.
이러한 참여 수준은 사용자들이 클라우드와 자체 데이터 센터에서 실행되는 서버 모두에서 엔비디아 AI를 통해 뛰어난 성능을 얻을 수 있다는 것을 입증한다.
모든 워크로드에 걸친 성능
엔비디아의 에코시스템 파트너들은 MLPerf가 AI 플랫폼 및 공급업체를 평가하는 고객에게 유용한 도구라는 것을 인식하고 이에 참여하고 있다.
이 벤치마크는 컴퓨터 비전, 번역 및 강화 훈련, 생성형 AI 및 추천 시스템 등 사용자가 중요하게 생각하는 워크로드를 다룬다.
MLPerf는 공정하고 객관적인 테스트이기 때문에 사용자는 그 결과를 바탕으로 정보에 입각한 구매 결정을 내릴 수 있다. 이러한 벤치마크는 암(Arm), 바이두(Baidu), 페이스북 AI(Facebook AI), 구글(Google), 하버드, 인텔(Intel), 마이크로소프트(Microsoft), 스탠퍼드, 토론토 대학교를 포함한 광범위한 그룹의 지지를 받고 있다.
MLPerf 결과는 H100, L4 및 엔비디아 젯슨(Jetson) 플랫폼에서 AI 트레이닝, 추론 및 HPC 벤치마크를 통해 오늘부터 확인할 수 있다. 또한 향후 MLPerf 라운드에서도 엔비디아 그레이스 호퍼 시스템에서 제출할 예정이다.
에너지 효율의 중요성
AI의 성능 요구사항이 증가하고 있다. 따라서 그 성능을 효율적으로 달성하는 방법을 더욱 개선해야 하며 이것이 바로 가속컴퓨팅이 하는 일이다.
엔비디아 GPU로 가속화된 데이터 센터는 더 적은 수의 서버 노드를 사용하므로 랙(rack) 공간과 에너지를 절약할 수 있다. 또한 가속화된 네트워킹은 효율성과 성능을 향상시키며, 지속적인 소프트웨어 최적화로 인해 동일한 하드웨어에서 뛰어난 성능 향상을 이끌어 낼 수 있다.
에너지 효율적인 성능은 환경과 비즈니스에도 유익하다. 성능이 향상되면 시장 출시가 단축되고 기업은 더 고급 애플리케이션을 구축할 수 있으며 에너지 효율은 비용을 절감한다. 엔비디아는 실제로 최신 그린 500 리스트(Green500 list)의 상위 30개 슈퍼컴퓨터 중 22개 슈퍼컴퓨터를 지원하고 있다.
누구나 사용할 수 있는 소프트웨어
엔비디아 AI 플랫폼의 소프트웨어 계층인 엔비디아 AI 엔터프라이즈(AI Enterprise)는 업계를 선도하는 가속 컴퓨팅 인프라에서 최적화된 성능을 구현한다. 이 소프트웨어는 기업 데이터 센터에서 AI를 실행하는 데 필요한 엔터프라이즈급 지원, 보안 및 안정성이 함께 제공된다.
이 테스트에 사용된 모든 소프트웨어는 MLPerf 저장소에서 사용할 수 있으므로 누구나 글로벌 수준의 결과를 얻을 수 있다.
최적화는 엔비디아의 GPU 가속 소프트웨어 카탈로그인 NGC에서 사용할 수 있는 컨테이너에 지속적으로 반영된다.
여기에서 엔비디아의 MLPerf 성능과 효율성을 높이는 최적화에 대해 자세한 내용을 확인할 수 있다.
엔비디아, NVIDIA, MLPerf, 벤치마크, H100, 텐서 코어 GPU, Tensor Core GPU, 생성형, AI, 인공지능, 구동, 대규모 언어 모델, LLM, 최고, AI 성능, 제공, 표준 설정










