

컴퓨텍스 | 엔비디아 코스모스 3, 비전 추론·멀티모달 생성 통합해 피지컬 AI 행동 예측 구현
엔비디아(www.nvidia.co.kr)가 아시아 최대 ICT 전시회 컴퓨텍스(COMPUTEX) 2026을 맞이해 개최한 엔비디아 GTC 타이베이(NVIDIA GTC Taipei)에서 새로운 오픈 월드 파운데이션 모델 ‘엔비디아 코스모스 3(Cosmos 3)’를 공개했다.
현실 세계는 항상 움직인다. 로봇, 자율주행차, 스마트 공간을 포함한 피지컬 AI 시스템이 자율적으로 작동하려면 단순히 눈앞의 화면이나 발생 원인을 이해하는 것을 넘어 다음에 일어날 상황을 예측해야 한다.

예컨대 물류창고의 로봇은 처음 보는 물체 배치와 마주할 수 있고, 도로 위 자율주행차는 주차된 차량 사이에서 갑자기 튀어나오는 보행자에 대응해야 한다. 공장 내 안전 시스템 역시 지게차의 단순 존재 감지를 넘어 이동 방향을 미리 예측해야 한다.
그러나 이러한 시나리오를 현실 세계에서 직접 포착하고 재현하는 작업은 속도가 느리고 비용이 많이 들 뿐 아니라 대규모 반복이 거의 불가능하다.
엔비디아가 이번에 발표한 코스모스 3 모델은 이러한 한계를 해결한다. 이는 단일 모델 내에서 텍스트, 비디오, 이미지, 주변 음향, 행동 전반의 비전 추론과 멀티모달 생성을 결합해 개발자가 물리적 컨텍스트를 갖춘 세계 데이터를 생성하도록 지원한다.

코스모스 3는 인식, 예측, 동작을 지원한다
코스모스 3의 트랜스포머 혼합(mixture-of-transformers) 아키텍처는 추론 블록이 먼저 장면의 상황을 해석한 뒤, 생성 블록이 해당 컨텍스트를 활용해 합성 비디오부터 로봇 작업 데이터까지 물리적 법칙에 부합하는 결과물을 생성하도록 이끈다.
실제 로봇 작업을 위한 행동 데이터 생성
코스모스 3는 다양한 데이터 훈련을 바탕으로 장면, 움직임, 로봇 행동의 연관 관계를 폭넓게 이해하는 범용 기반 모델이다. 특히 관절 각도, 그리퍼 위치, 궤적 좌표처럼 로봇의 작업 수행에 필요한 수치적 행동 데이터를 직접 생성하는 네이티브 액션 생성 기능을 갖춘 옴니모델(omnimodel)이다.
로봇이 학습하려면 단순 이미지나 비디오 이상의 데이터가 필요하다. 일례로 물건을 집어 옮기는 집기 작업의 경우, 주변 환경 내에서 물체에 도달하고 움켜쥐고 이동해 배치하도록 안내하는 행동 신호가 필수적이다. 개발자는 특정 하드웨어 형태, 카메라 배치, 작업 공간, 개별 작업에 맞춰 코스모스 3를 파인튜닝할 수 있다.
현재 엔비디아 기어(GEAR) 팀은 코스모스 3를 활용해 임바디드 에이전트가 게임, 시뮬레이션, 실제 로봇 환경에서 추론하고 움직이며 행동하는 법을 학습하도록 돕는 비디오 액션 모델을 개발 중이다.

음성 프롬프트: 바나나를 모두 접시에 올려주세요
애자일 로봇(Agile Robots)은 산업용 작업을 자율적이고 정밀하며 효율적으로 처리하는 토르 3(Thor 3)나 FR3 등 휴머노이드와 다양한 형태의 로봇을 구축하고 있다. 애자일 로봇은 코스모스 3를 도입해, 대규모로 다양한 작업 궤적을 생성하는 정책 개발을 위한 행동 조건부 로봇 데이터를 생성하고 있다.

프롬프트: 코어 전선을 집어 양팔을 사용해 쓰레기통에 넣으세요
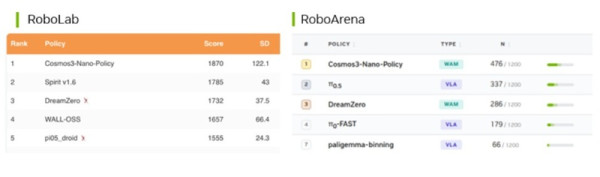
코스모스 3 나노의 사후 훈련된 정책은, 언어 기반 과제에서 시뮬레이션을 통해 정책을 테스트하는 로보랩(RoboLab)과 실제 환경에서 드로이드(DROID) 로봇을 대상으로 정책을 비교하는 로보아레나(RoboArena)에서 선두를 달리고 있다.
스마트 시티와 움직이는 공간에 대한 추론
코스모스 3는 장면 전반을 추론해 움직이는 객체를 식별하고, 경로가 교차하는 지점이나 다음에 이어질 미래 상태를 예측할 수 있다. 나아가 상세한 캡션, 예측된 장면 변화, 다양한 시나리오 변형을 생성함으로써 개발자가 산업 환경과 인프라 환경용 비전 AI 에이전트의 이해, 예측, 경보 기능을 유기적으로 연결하도록 지원한다.

코스모스 3를 활용한 추론을 통한 로봇 행동 계획 추적
이를 통해 교통 시스템, 공장, 물류창고, 공공장소 내 비디오 시스템은 시간에 따른 활동을 해석하고 이상 징후를 감지한다. 또한 복잡한 환경 전반에서 벌어지는 상황에 대해 운영자에게 더 풍부한 컨텍스트를 제공하게 된다.
링커 비전(Linker Vision)은 엔비디아 피지컬 AI와 디지털 트윈 기술을 활용해 지능형 스마트 시티와 산업용 솔루션을 구축하고 있다. 링커 비전은 워크플로우 일환으로 코스모스 3의 비전 언어 추론 기능을 도입해 실시간 카메라 스트림을 분석하고, 공간 컨텍스트를 이해하며, 수천 개 피드 전반에서 가치 있는 인사이트 추출과 근본 원인 분석을 수행 중이다.
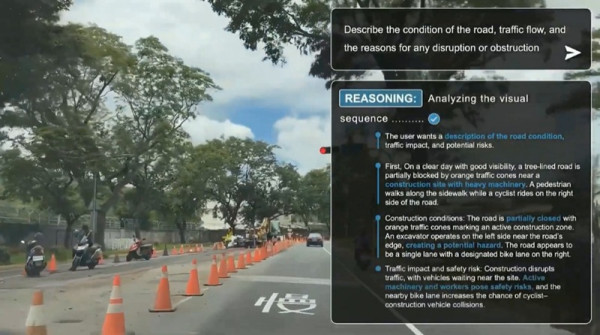
링커 비전은 코스모스 기술을 기반으로 비전 AI를 활용해 도시 운영을 최적화한다.
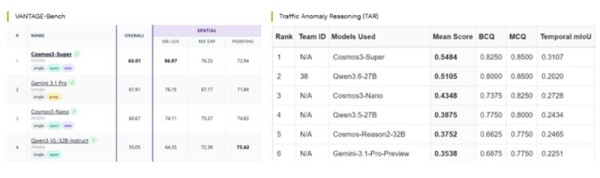
코스모스 3는 스마트 인프라 장면 이해 능력을 평가하는 빈티지-벤치(VANTAGE-Bench)와 교통 이상 현상 추론 능력을 평가하는 TAR 챌린지에서 1위를 차지한 오픈 비전 언어 모델이다.
시간에 따른 예외적인 롱테일 시나리오 구현
충돌 사고나 드물게 발생하는 예외 상황 등은 휴머노이드, 로봇 팔, 수술 로봇이 현실 세계에 대비하는 데 가장 중요한 학습 사례다. 그러나 이를 안전하고 반복적이며 대규모로 포착하기는 어렵다.
코스모스 3는 현실 세계가 시간에 따라 변하는 방식을 학습시키는 비디오 기반 모델로서, 물리적으로 타당한 비디오 시퀀스 생성을 지원한다.
피지컬 AI 개발자는 프레임 단위로 조건이 바뀌는 상황에서도 이렇게 생성된 예시를 활용해 실제 주행 데이터와 병행하는 합성 데이터 워크플로우와 미래 상태 예측을 고도화할 수 있다.

이미지-비디오 프롬프트: 자동차가 구불구불한 커브를 여러 번 통과하는 고속 레이싱 경기
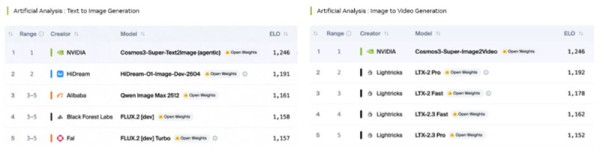
코스모스 3의 변형 모델들이 아티피셜 애널리스트(Artificial Analysis)의 오픈 웨이트 리더보드에서 1위를 차지하고 있다.
또한 코스모스 3는 피직스-IQ(Physics-IQ), R-벤치(R-Bench), PAI-벤치(PAI-Bench)를 비롯한 다양한 월드 생성 벤치마크 리더보드에서도 선두를 달리고 있다.
코스모스 3 이용 정보
개발자는 build.nvidia.com에서 코스모스 3를 체험할 수 있으며, 허깅페이스(Hugging Face)에서 오픈 모델을 다운로드할 수 있다. 또한 깃허브(GitHub) 리소스를 활용해 모델을 맞춤화하고 합성 데이터를 생성할 수 있으며, 엔비디아 NIM 마이크로서비스를 통해 배포 가능하다.
리눅스 재단(Linux Foundation)의 오픈MDW(OpenMDW) 1.1 라이선스를 기반으로 제공되므로, 개발자는 단일 모델 중심 라이선스 하에 피지컬 AI 워크플로우 전반에서 코스모스 모델 자료를 활용할 수 있다. 이 라이선스는 가중치, 아키텍처, 문서, 데이터 세트, 벤치마크, 코드를 포함한 리소스의 훈련, 수정, 기여, 재배포, 배포 과정을 한층 간소화한다.
여기에서 엔비디아 창립자 겸 CEO 젠슨 황(Jensen Huang)의 GTC 타이베이 기조 연설을 시청할 수 있으며, 여기에서 다양한 피지컬 AI 세션을 확인할 수 있다.
여기에서 소프트웨어 제품 정보에 관한 공지 사항을 확인할 수 있다.
엔비디아, NVIDIA, 컴퓨텍스, COMPUTEX, 2026, 엔비디아 코스모스 3, Cosmos 3, 비전, 추론, 멀티모달, 생성, 통합해, 피지컬 AI, 행동, 예측, 구현











