

IT | 엔비디아 지포스 RTX·RTX GPU·DGX 스파크, 오픈클로(OpenClaw) 로컬 실행 지원
엔비디아(www.nvidia.co.kr)가 엔비디아(NVIDIA) RTX GPU와 DGX 스파크(DGX Spark)에서 오픈클로(OpenClaw)와 거대 언어 모델(large language model, LLM)을 완전히 로컬로 실행하는 방법을 공개했다.
오픈클로(구 클로드봇(Clawdbot)·몰트봇(Moltbot))는 사용자의 컴퓨터에서 구동되는 ‘로컬 우선(local-first)’ AI 에이전트로, 다양한 기능을 결합해 유용한 어시스턴트 역할을 수행한다. 대화를 기억하고 이에 맞춰 스스로를 조정하는 것은 물론, 로컬 환경에서 지속적으로 실행되며 파일과 앱의 맥락 정보를 활용하고 새로운 ‘스킬’을 통해 기능을 확장할 수 있는 점에서 주목받고 있다.

오픈클로의 주요 활용 사례는 다음과 같다.
- 개인 비서: 이메일, 달력, 파일에 접근해 일정을 자율적으로 관리할 수 있다. 파일과 이전 메일의 맥락을 기반으로 이메일 답장을 작성하고, 사전에 요청한 알림을 전송하며, 달력에서 가능한 일정을 확인해 회의를 자동으로 조율할 수 있다.
- 선제적 프로젝트 관리: 사용 중인 이메일이나 메시징 채널을 통해 프로젝트 진행 상황을 정기적으로 확인하고, 상태 보고를 전송하거나 필요시 후속 조치와 알림을 보낼 수 있다.
- 연구 에이전트: 앱에서 제공되는 개인화된 맥락을 바탕으로 인터넷 검색 결과와 파일을 결합한 보고서를 생성할 수 있다.
오픈클로는 로컬 또는 클라우드 환경에서 실행 가능한 LLM을 기반으로 구동된다. 다만 클라우드 기반 LLM은 상시 실행되는 오픈클로의 특성으로 인해 상당한 비용이 발생할 수 있으며, 개인 데이터를 업로드해야 하는 부담이 있다.
엔비디아 RTX GPU와 DGX 스파크에서 오픈클로와 LLM을 완전한 로컬 환경으로 실행할 경우, 비용 절감과 데이터 프라이버시 유지를 동시에 실현할 수 있다.
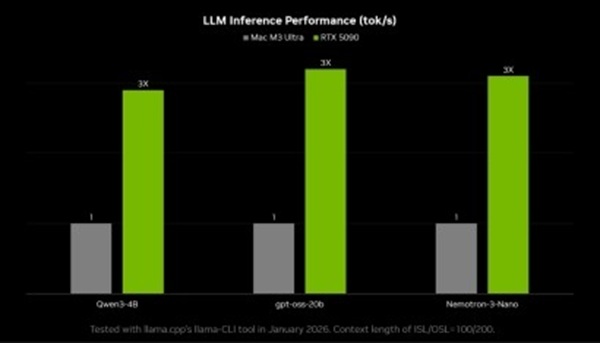
엔비디아 RTX GPU는 AI 연산을 가속하는 텐서 코어(Tensor Core)와 오픈클로 실행에 필요한 올라마(Ollama), 라마.cpp(Llama.cpp) 등 다양한 도구를 지원하는 쿠다(CUDA) 가속을 통해 워크플로우에 최적의 성능을 제공한다. 특히 DGX 스파크는 상시 구동 환경에 최적화된 설계와 128GB 메모리를 기반으로 더 큰 로컬 모델을 실행할 수 있어, 높은 정확도와 성능을 구현할 수 있다.
시작 전 주의 사항
AI 에이전트 사용 시에는 위험을 인지하고 이를 최소화하기 위한 주의가 필요하다. 자세한 내용은 오픈클로 웹사이트를 통해 확인할 수 있다.
이와 같은 에이전트에는 다음과 같은 두 가지 주요 위험이 존재한다.
- 개인 정보 또는 파일이 유출되거나 도난당할 수 있다.
- 에이전트 자체 또는 연결된 도구를 통해 악성 코드나 사이버 공격에 노출될 수 있다.
모든 위험으로부터 완전히 보호할 수 있는 방법은 없으므로 사용에 각별한 주의가 필요하다. 다음은 오픈클로 테스트 과정에서 적용할 수 있는 주요 보안 조치다.
- 개인 데이터가 없는 별도의 PC 또는 가상 머신에서 오픈클로를 실행하고, 에이전트에 접근을 허용할 데이터만 복사해 사용한다.
- 기존 계정에 대한 접근 권한을 부여하지 않고, 에이전트 전용 계정을 생성해 필요한 정보 또는 접근 권한만 제한적으로 공유한다.
- 활성화하는 스킬은 신중히 선택하며, 가능하면 커뮤니티 검증을 거친 스킬 위주로 테스트를 진행한다.
- 웹 UI, 메시징 채널 등 오픈클로 어시스턴트 접근을 위해 사용하는 채널이 로컬 네트워크나 인터넷을 통해 무단으로 노출되지 않도록 설정한다.
- 사용 환경에 따라 가능할 경우 인터넷 접근을 제한한다.
윈도우(Windows)에 오픈클로를 설치하려면 리눅스용 윈도우 하위 시스템(Windows Subsystem for Linux, WSL)을 사용해야 한다. 파워셸(PowerShell)에서의 네이티브 설치도 가능하지만 불안정성으로 인해 권장되지 않는다. 리눅스용 윈도우 하위 시스템 설치: WSL이 이미 설치돼 있다면 다음 오픈클로 설치 섹션으로 건너뛸 수 있다. WSL을 설치하려면 다음 절차를 따라야 한다: (참조 링크)
로컬 모델 설정: 오픈클로는 RTX GPU에서 로컬로 실행되는 LLM이나 클라우드 LLM을 활용할 수 있다. 이 섹션에서는 LM 스튜디오(LM Studio) 또는 올라마를 사용해 오픈클로를 로컬에서 실행하도록 설정하는 방법을 안내한다. 답변 품질은 LLM의 크기와 성능에 따라 달라진다. 따라서 가능한 많은 VRAM을 확보하는 것이 중요하다. GPU에서 다른 작업을 실행하지 않고, 필요한 스킬만 불러와 맥락을 최소화하는 등의 방법으로 대규모 LLM이 GPU를 최대한 활용할 수 있도록 해야 한다.
설치와 설정이 올바르게 완료되었는지 확인하려면 브라우저 창을 열고 액세스 토큰이 포함된 오픈클로 URL을 입력한다. 신규(New)를 클릭한 뒤, 메시지를 입력해 응답이 돌아오는지 확인한다. 응답이 나오면 정상적으로 설정이 완료된 것이다. 또한 오픈클로가 현재 어떤 모델을 사용하고 있는지 확인할 수 있으며 게이트웨이 채팅 UI에서 /model MODEL_NAME을 입력해 모델을 전환할 수 있다.
- WSL을 통한 Windows 설치(wsl --install)
- 오픈클로 설치 : WSL 창에서 curl -fsSL https://openclaw.ai/install.sh | bash로 설치
- LM 스튜디오(LM Studio) 또는 Ollama를 사용한 로컬 LLM 구성
- GPU 메모리 등급별 권장 모델 조합 : 8~12GB GPU의 소형 4B 모델부터 128GB 메모리 탑재한 DGX Spark의 gpt-oss-120b
오픈클로 사용 방법에 대한 자세한 내용은 오픈클로 웹사이트를 방문해 확인할 수 있다.
아울러 새로운 스킬을 추가하는 것도 가능하다. 다만, 스킬 추가는 추가적인 위험을 수반하므로 신중히 선택해야 한다. 새로운 스킬을 추가하는 방법은 다음과 같다.
- 오픈클로에게 스킬로 스스로를 구성하도록 요청
- 웹 UI 사이드바를 통해 스킬 활성화
- 클로허브(Clawhub)에서 커뮤니티 제작 스킬 탐색
엔비디아, NVIDIA, 지포스 RTX, RTX GPU, DGX 스파크, 오픈클로, OpenClaw, 로컬, 실행, 지원











