

IT | FP8 대비 최대 1.9배 향상, 엔비디아 NVFP4로 AI 훈련·추론 성능과 효율성 동시 향상
엔비디아(www.nvidia.co.kr)가 NVFP4 정밀도를 기반으로 AI 훈련과 추론 성능을 크게 향상시킬 수 있다고 밝혔다. 엔비디아(NVIDIA)는 NVFP4를 통해 높은 정확도를 유지하면서도 처리량과 에너지 효율을 동시에 개선해 차세대 AI 워크로드 최적화를 지원한다.
최신 AI 모델의 규모와 복잡성이 지속적으로 증가함에 따라 훈련과 추론에 필요한 컴퓨팅 성능 또한 급격히 증가하고 있다. 이는 무어의 법칙으로는 더 이상 감당하기 어려운 수준이다. 이러한 한계를 극복하기 위해 엔비디아는 고도의 공동 설계(codesign)를 채택했다. 여러 칩과 방대한 소프트웨어를 아우르는 통합 설계는 AI 팩토리의 성능과 효율성을 세대별로 비약적으로 향상시키고 있다.

낮은 정밀도의 AI 포맷은 컴퓨팅 성능과 에너지 효율성 향상의 핵심이다. 높은 정확도를 유지하면서 초저정밀도 수치 연산의 이점을 AI 훈련과 추론에 적용하려면 기술 스택의 모든 계층에 걸친 광범위한 엔지니어링이 필요하다. 이는 새로운 포맷 생성, 실리콘 구현, 다양한 라이브러리 지원, 그리고 생태계와의 긴밀한 협력을 통한 훈련 레시피와 추론 최적화 기술 배포에 이르기까지 전 과정에 걸쳐 이뤄진다. 엔비디아 GPU용으로 개발된 NVFP4는 엔비디아 블랙웰(Blackwell)부터 도입됐으며, 4비트 부동소수점 정밀도를 기반으로 고정밀 포맷에 준하는 정확도를 유지하면서도 성능과 에너지 효율을 동시에 향상시킨다.
AI 훈련과 추론 성능을 극대화하기 위해 주목해야 할 NVFP4의 세 가지 핵심 요소는 다음과 같다.
1. 블랙웰 아키텍처와 그 이상의 플랫폼에서 훈련과 추론 성능을 획기적으로 향상
엔비디아 블랙웰 울트라(Ultra) GPU는 최대 15페타플롭스의 고밀도 NVFP4 처리량을 제공하며, 이는 동일 GPU에서 FP8 대비 3배에 달한다. 이러한 성능 향상은 단순한 이론적 수치에 그치지 않고, 훈련과 추론 워크로드의 실측 성능에서도 명확히 드러난다.
추론 영역에서는 최근 엔비디아 기술 블로그에서 확인할 수 있듯이, FP8에서 NVFP4로 전환하면 6,710억 매개변수를 가진 대표적인 전문가 혼합(mixture-of-experts, MoE) 모델인 딥시크-R1(DeepSeek-R1)에서 동일한 상호작용 수준에서도 토큰 처리량이 크게 향상된다. 또한 더 높은 토큰 속도에서도 처리량이 증가하며 전반적인 사용자 경험을 개선할 수 있다.
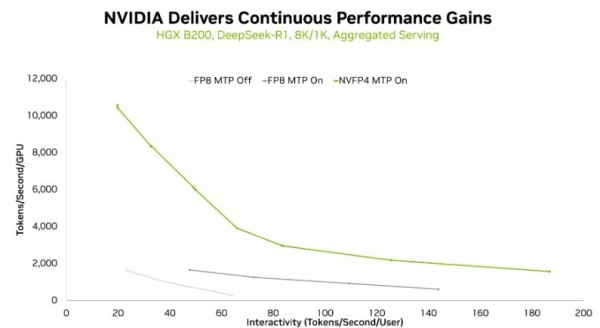
HGX B200에서 MTP 미적용 FP8, MTP 적용 FP8, MTP 적용 NVFP4의 처리량 대 상호작용 곡선(8K/1K 시퀀스 길이, 집계 서비스 기준)
엔비디아는 최근 NVFP4 훈련 레시피를 공개하며, NVFP4의 성능 이점을 모델 훈련 단계까지 확장했다. 이를 통해 모델 개발자가 더 빠르고 저렴한 비용으로 AI를 훈련할 수 있도록 지원한다.
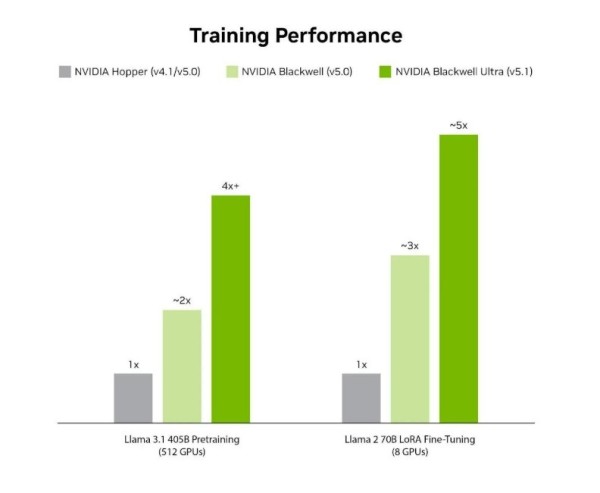
라마(Llama) 3.1 405B 사전 훈련과 라마 2 70B LoRA 파인튜닝 성능을 각각 512-GPU와 8-GPU 규모에서 평가했다.
최신 MLPerf 훈련(MLPerf Training) 벤치마크에서는 총 512개의 블랙웰 울트라 GPU로 구성된 여러 엔비디아 GB300 NVL72 시스템이 NVFP4 정밀도를 활용해 라마 3.1 405B 사전 훈련 벤치마크를 64.6분 만에 완료했다. 이는 이전 라운드에서 FP8 정밀도로 동일한 벤치마크를 수행한 512개의 블랙웰 GPU 기반 엔비디아 GB200 NVL72 시스템 대비 1.9배 빠른 성능이다.
향후 엔비디아 루빈(Rubin) 플랫폼은 NVFP4 기반 훈련과 추론 성능을 한층 더 끌어올릴 전망이다. 루빈 플랫폼은 NVFP4 기준 훈련 연산에서 35페타플롭스, 트랜스포머 엔진(Transformer Engine) 기반 추론에서 50페타플롭스의 성능을 제공하며, 이는 블랙웰 대비 각각 3.5배, 5배 향상된 수준이다.
2. 업계 벤치마크를 통해 입증된 뛰어난 정확도 제공
MLPerf 훈련과 추론(Inference)의 비공개 부문 평가 제출물이 유효하려면 벤치마크에서 명시한 정확도 요건을 충족해야 한다. 추론의 경우 응답이 특정 정확도 기준을 충족해야 하며, 훈련의 경우 모델이 특정 품질 목표에 도달하도록 훈련돼야 한다. 즉, 훈련 과정이 수렴해야 한다.
엔비디아는 최신 MLPerf 훈련에서 블랙웰과 블랙웰 울트라 GPU 기반 NVFP4를 적용해 모든 거대 언어 모델(large language model, LLM) 테스트 항목에서 비공개 부문 결과를 성공적으로 제출했다. 또한 엔비디아는 MLPerf 추론 부문에서 NVFP4를 활용한 다양한 모델과 시나리오에 걸쳐 결과를 제출했다. 여기에는 딥시크-R1, 라마 3.1 8B과 405B, 라마 2 70B가 포함된다. 엔비디아는 NVFP4로 양자화된 모델을 사용하면서도 엄격한 벤치마크 요구사항을 충족했다.
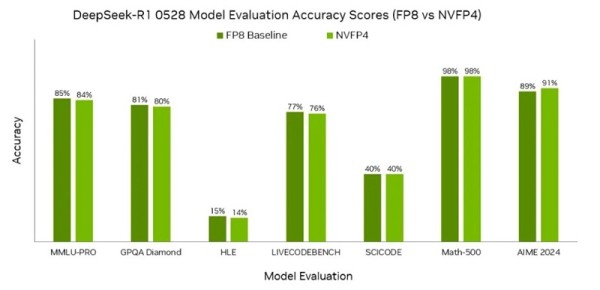
딥시크-R1 모델 평가 점수에서 NVFP4가 FP8 기준선의 정확도와 매우 유사하게 일치함을 보여준다.
3. 광범위하고 지속적으로 성장하는 생태계 지원
엔비디아 모델 옵티마이저(Model Optimizer), LLM 컴프레서(LLM Compressor), 토치.ao(torch.ao)와 같은 라이브러리를 통해 개발자는 고정밀도로 훈련된 모델을 NVFP4로 양자화한다. 또한, 정확도를 유지하면서 긴 컨텍스트와 대량 배치 크기를 지원하기 위해 NVFP4 KV 캐시를 구현할 수 있다. 엔비디아 텐서RT-LLM(TensorRT-LLM), vLLM, SGLang 등 인기 추론 프레임워크도 현재 NVFP4 포맷의 모델 실행을 지원하며, NVFP4 변형 모델을 제공한다. 예를 들어, 허깅 페이스(Hugging Face)에서 개발자는 라마 3.3 70B, 플럭스.2(FLUX.2), 딥시크-R1-0528, 키미-K2- 씽킹(Kimi-K2-Thinking), 큐원3-235B-A22B(Qwen3-235B-A22B), 엔비디아 네모트론 나노(Nemotron Nano)와 같은 배포 준비가 완료된 NVFP4 버전을 찾을 수 있다.
또한 다양한 모델에서 프로덕션 환경의 추론 처리량을 높이기 위해 NVFP4를 채택하고 있다. 블랙 포레스트 랩스(Black Forest Labs), 래디컬 뉴메릭스(Radical Numerics), 코그니션(Cognition), 레드햇(Red Hat) 등이 대표적인 기업들이다.
블랙 포레스트 랩스는 엔비디아와 협력해 블랙웰 기반에서 플럭스.2의 NVFP4 추론을 확장했다. 블랙 포레스트 랩스의 공동 창립자 겸 CEO인 로빈 롬바흐(Robin Rombach)는 “쿠다 그래프(CUDA Graphs), 토치.컴파일(torch.compile), NVFP4 정밀도, 티캐시(TeaCache)와 같은 최적화 기법을 계층화해 단일 B200에서 최대 6.3배의 속도 향상을 달성했다. 이를 통해 지연 시간을 획기적으로 줄이고, 더 효율적인 프로덕션 환경 구축이 가능해졌다”고 말했다.
래디컬 뉴메릭스는 NVFP4를 활용해 과학 분야 월드 모델의 확장을 가속화하고 있다. 래디컬 뉴메릭스의 공동 창립자 겸 최고 AI 과학자 마이클 폴리(Michael Poli)는 “과학 데이터는 언어와 달리 단일 모달리티 기반의 전통적인 자기회귀 방식으로는 한계가 있으며, 매우 긴 컨텍스트 처리와 견고한 멀티모달 결합이 요구된다”고 말했다. 그는 새로운 아키텍처의 사전 훈련과 사후 훈련에 저정밀도 방식을 활용하는 것에 “매우 긍정적”이라고 덧붙였다.
코그니션의 스티븐 카오(Steven Cao) 연구원도 역시 대규모 강화학습에서 NVFP4를 적용해 “지연 시간과 처리량 측면에서 유의미한 개선”을 확인했다고 설명했다.
레드햇은 NVFP4 양자화를 통해 LLM 워크로드를 확장하고 있다. 이를 통해 개발자들은 제한된 메모리 환경 내에서 프론티어 모델과 MoE 모델 모두에서 기준선 수준의 정확도를 유지할 수 있다. NVFP4는 품질 저하 없이 활성값과 가중치의 메모리 사용량을 크게 줄여, 레드햇 엔지니어들이 기존 인프라를 활용해 더 킨 컨텍스트와 높은 동시 처리 환경에서 최신 LLM을 훈련하고 서비스할 수 있도록 지원한다.
엔비디아 트랜스포머 엔진 라이브러리는 NVFP4 훈련 레시피를 구현하고 있으며, 메가트론-브릿지(Megatron-Bridge)와 같은 훈련 프레임워크를 통해 개발자들이 이를 손쉽게 활용할 수 있도록 지원한다. 엔비디아는 또한 NVFP4 기반 훈련의 성능과 효율성을 전체 생태계로 확장하기 위해 지속적인 기술 혁신과 협력을 이어가고 있으며, 더 복잡하고 고도화된 모델을 더욱 빠르고 효율적으로 훈련할 수 있는 기반을 마련하고 있다.
자세히 알아보기
NVFP4는 엔비디아 블랙웰과 루빈 플랫폼 전반에서 큰 폭의 성능 향상을 제공한다. 엔비디아의 긴밀한 공동설계를 통해 이러한 성능 향상은 모델 훈련과 추론 모두에서 높은 정확도를 유지하면서 구현된다. 또한 주요 오픈소스 LLM의 NVFP4 버전이 폭넓게 제공됨에 따라, 서비스 제공업체는 더 높은 처리량과 더 낮은 토큰당 비용으로 모델을 운영할 수 있다.
여기에서 루빈 플랫폼의 아키텍처 혁신과 향상된 NVFP4 기술이 AI 훈련과 추론 성능을 어떻게 한층 끌어올리는지에 대한 자세한 내용을 확인할 수 있다.
엔비디아, NVIDIA, FP8, 대비, 최대, 1.9배, 향상, NVFP4, 정밀도, 로, AI 훈련, 추론, 성능과, 효율성, 동시










