

IT | 서울과학기술대학교 임경태 교수팀, 텍스트·이미지 동시 처리하는 최초의 한국어 특화 LMM ‘Bllossom-V 3.1’ 공개
서울과학기술대학교(이하 서울과기대) 멀티모달 언어처리 연구실(MLP) 임경태 교수팀이 HuggingFace 리더보드를 통해 지난 9월 4일 최초의 한국어 특화 시각-언어모델인 ‘Bllossom-V 3.1’을 공개했다고 밝혔다.
해당 모델은 서울과기대와 테디썸이 공동 구축한 언어모델인 ‘Bllossom’을 기반으로 이미지 처리를 위한 추가적인 훈련과정을 거쳐 개발된 시각-언어모델이다. 한글과 영어 두 가지 언어를 지원하며 텍스트뿐만 아니라 이미지까지 처리 가능하다. 이번 Bllossom-V 3.1의 공개는 HuggingFace 최초의 한국어 특화 LMM을 선보였다는 데 의미가 크다.
최초의 한국어 특화 LMM인 Bllossom-V 3.1 개발에 핵심적 역할을 한 데이터는 과학기술정보통신부가 주최하고 한국지능정보사회진흥원(NIA)에서 주관해 진행된 ‘문서 생성 및 정보 검색 데이터’ 과제를 통해 제작됐다. 해당 과제는 멀티모달 데이터 전문기업 미디어그룹사람과숲(이하 사람과숲)이 총괄로 참여해 유클리드소프트와 함께 전문성 있는 고품질 데이터를 구축했다.
또한 Bllossom-V 3.1은 서울과기대와 테디썸이 공동 개발한 계층연결(Layer Aligning) 방법을 적용한 대량의 한국어, 영어 사전학습을 완료한 모델로 2개 국어를 안정적으로 지원한다. 추가로 연구팀에서 직접 구축한 MVIF 한국어-영어 병렬 시각 말뭉치 데이터를 적용해 영어 성능의 하락 없이 한국어 성능을 대폭 향상시켰다는 평가를 받았다. 시각-언어 모델의 사전학습을 위해 필요한 방대한 양의 컴퓨팅 자원은 인공지능산업융합사업단(AICA)의 지원을 받았다.
모델 학습용 데이터 구축 총괄을 맡았던 사람과숲 한윤기 대표는 “고품질 데이터 구축을 통해 최초의 한-영 시각-언어 공개모델을 만드는 데 일조한 것에 큰 보람을 느낀다”며 “앞으로도 다양한 용도로 활용할 수 있는 공개 데이터 제작에 기여하겠다”고 말했다.
Bllossom-V 3.1 모델은 여기에서 만나볼 수 있다.
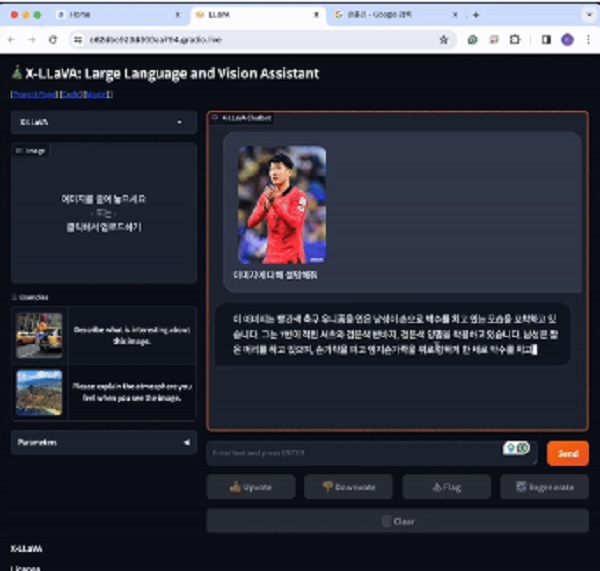
미디어그룹사람과숲, humanf, 서울과학기술대학교, 임경태 교수팀, 텍스트·이미지, 동시 처리, 최초의, 한국어 특화, LMM, Bllossom-V 3.1, 공개










