

PC | 40년 동안 이루어진 가장 큰 아키텍처의 변화, 인텔 메테오 레이크 아키텍처 공개
인텔 이노베이션 2023(Intel Innovation 2023)을 통해 차세대 프로세서에 적용할 메테오 레이크(Meteor Lake) 아키텍처의 보다 자세한 내용이 공개됐다.
메테오 레이크는 인텔의 첫 번째 타일(Tile) 기반 소비자용 CPU 아키텍처이자 모놀리식 디자인(Monolithic Design) 대신 칩렛(Chiplets)으로 성능 향상 및 전력 효율에 큰 변화가 예상된다. 새로운 설계와 제조 방식의 도입으로 인텔은 지난 40년 동안 이루어진 가장 큰 아키텍처의 변화라고 밝혔다.

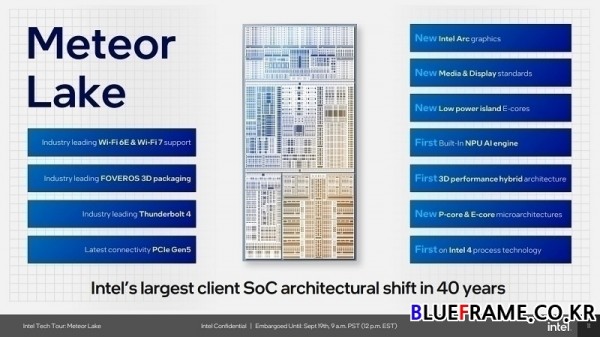
또한 와트당 성능의 효율을 높여 그 어느 때보다 적은 전력을 사용하며 Xe-LPG 그래픽 아키텍처는 2배 향상된 와트당 성능, NPU는 CPU 대비 최대 8배 더 높은 효율을 제공한다. 메테오 레이크 아키텍처는 향후 10년 간 인텔 프로세서 디자인의 근간이 될 것으로 알려졌으며 인텔 3(Intel 3)을 대비한 포석이다.
인텔은 12월 14일 메테오 레이크 아키텍처를 적용한 모바일용 프로세서 첫 제품을 출시할 예정이며 구체적인 라인업 등은 아직 공개하지 않았다.

인텔은 기존 12세대 및 13세대는 CPU 코어와 통합 GPU, I/O 기능을 하나의 모노리식 디자인으로 MCP(Multi-Chip Packaging)로 구현했으나 메테오 레이크부터는 타일(Tile)을 적용한 것이 특징이다. 타일은 CPU 코어와 언코어, 통합 GPU, I/O 등의 여러 개의 칩을 분할하는 것을 말한다. 웨이퍼의 다이 크기 등에 따른 낭비되는 공간을 줄일 수 있으며 각 칩의 가능성을 극대화 가능해 물리적 및 경제적으로 유리하다. 각 칩을 작은 조각으로 나누어진 것을 함께 패키징하므로 더 복잡해지고 보다 정교한 설계가 필요하다.
타일(Tile)은 P-코어(P-Core, 고성능 코어)와 E-코어(E-Core, 고효율 코어)를 포함하는 컴퓨트 타일(Compute Tile), LP E-코어(Low Power Island E-Cores), 메모리 컨트롤러 & DDR, 8K HDR & AV1, Wi-Fi 6E & Wi-Fi 7와 블루투스(Bluetooth), HDMI 2.1와 DP 2.1, NPU(Neural Processing Unit) AI(인공지능) 가속 엔진 등을 포함하는 SOC 타일(SOC Tile), 인텔 Xe-LPG 아키텍처 기반 통합 GPU를 포함하는 그래픽스 타일(Graphics Tile), 썬더볼트 4(Thunderbolt 4)와 PCIe Gen5 등 각종 입출력 기능을 담당하는 I/O 타일(I/O Tile) 등 크게 4개로 구성된다.

4개의 타일은 서로 다른 공정 기술을 적용하며 인텔은 자체 공정을 고집해왔지만 메테오 레이크부터 달라진다. 컴퓨트 타일은 인텔 IDM 2.0 전략에 따라 인텔 4(Intel 4) 공정을 적용하며 극자외선 리소그래피(EUV lithography) 기술을 사용하는 인텔 최초의 클라이언트 칩이다. 통합 GPU의 그래픽스 타일은 AMD와 엔비디아(NVIDIA) 최신 GPU에 적용한 TSMC N5(5nm) 공정, SoC 타일과 I/O 타일은 TSMC N6(6nm) 공정을 이용한다. 이들은 고급 패키징 기술인 포베로스(Foveros) 3D 패키징으로 조립된 베이스 타일 위에 4개의 타일을 통합한다.
인텔 4 공정은 제조를 단순화하면서 수율과 면적 확장을 개선하는데 효율적으로 이전 세대 인텔 7(intel 7) 공정 대비 2배 밀도 향상과 20% 향상된 전력 효율을 제공한다. 주파수 향상에 따라 성능 개선도 예상된다. 이후 인텔은 인텔 3(Intel 3) 공정으로의 전환을 진행할 예정이다. 전력 효율 개선을 위해 인텔 스레드 디렉터를 통해 실시간 피드백받는 향상된 원격 측정 데이터도 추가한다.


인텔이 프로세서에 적용한 고급 패키징 기술로는 포베로스(Foveros) 3D 패키징과 임베디드 멀티 다이 인터커넥트 브리지(EMIB, Embedded Multi-die Interconnect Bridge)가 있으며 이들은 실리콘을 직접 쌓는 방식이다. EMIB는 2017년 처음 등장했고 인텔 최신 서버용 프로세서인 사파이어 래피즈(Sapphire Rapids)에 도입했으며 55um 피치 인터커넥트를 통해 임베디드 실리콘 브리지 위에 다이를 장착한다. 메테오 레이크의 포베로스는 2020년 레이크필드(LakeField)를 통해 구현되었고 3D 적층 방식으로 패키지 기판에 장착하는 방식이다.
포베로스 3D 패키징은 컴퓨트 코어와 I/O 및 그래픽스 코어 등 프로세서에 따라 타일을 자유롭게 변경할 수 있다. 더 높은 IPC 성능과 새로운 그래픽 프로세서 및 Wi-Fi 7과 같은 최신 I/O를 갖춘 더 빠른 코어를 갖춘 새로운 타일을 도입하는 것이 더 쉬워진다. 단일인 모놀리식 다이로 인텔은 각 타일에 서로 다른 제조 공정을 사용하고 이를 실리콘에 통합할 수 있으며 이러한 유연성은 혁신적이며 맞춤화 가능성을 제공하고 웨이퍼 수율을 향상시키는데 목적이 있다.

서로 다른 공정과 기능의 4개 타일을 결합하는 포베로스 3D 패키징이 메테오 레이크 SoC를 구축하는데는 FDI(Foveros Die Interconnect)를 사용하는 기본 타일을 포함한다. 22FFL 공정의 기본(베이스) 타일은 타일이 배치될 다양한 로직과 금속 레이어 모두에 대한 기반 역할을 하고 금속 레이어링이 포함된 마이크론 범프 피치 크기 36μm(36마이크로미터, 레이크필드 55um) 다이 투 다이 피치와 2GHz에서 0.15~0.3pJ/bit의 작동 전력을 가지며 전압과 암페어 및 주파수에 따라 변동되거나 달라질 수 있다. 마이크론 범프 피치는 제곱 밀리미터당 최대 770개, 크기는 향후 25um에서 18um까지 개선해 나가며 인텔은 HBI(Hybrid Bonding Interconnects)와 결합해 마이크론 범프 피치 크기를 1마이크로미터(1um)까지 개선할 수 있다고 설명했다.
포베로스 작동 전력은 0.15~0.3pJ/bit로 AMD 인피니티 패브릭(Infinity Fabric)이 <2 pJ/bit와 비교해 인텔은 데이터 전송 등 특정 부분에서 5-10배의 효율성을 제공할 것으로 예상된다. 인터커넥트 및 베이스 타일 성능은 mm 당 160GB/s로 대역폭이나 레이턴시 제약이 발생하지 않는다.
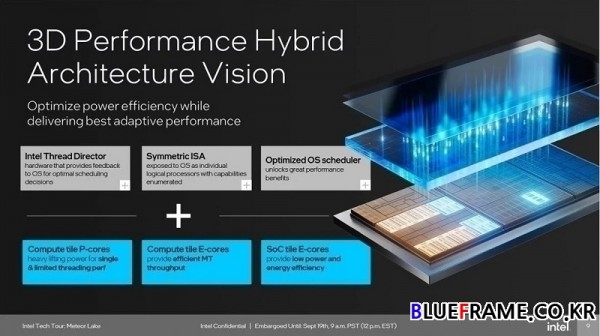

메테오 레이크의 컴퓨트 타일은 인텔 7(Intel 7) 공정 12세대 코어 프로세서 코드명 앨더레이크(Alder Lake) 및 13세대 코어 프로세서 코드명 랩터 레이크(Raptor Lake)와 같이 퍼포먼스 코어(Performance Core, P-Core)와 에피션트 코어(Efficient Core, E-Core)의 두 개의 X86 코어 타입을 데스크탑 최초로 통합한 고성능 하이브리드 아키텍처에 새롭게 SOC 타일에 도입한 LP E-코어(Low Power Island E-Cores)를 통합해 3D 고성능 하이브리드 아키텍처(3D Performance Hybrid Architecture)라고 부른다.

새로 업데이트된 E-코어는 코드명 크레스트몬트(Crestmont)로 기존과 같이 멀티태스킹을 위한 스루풋 효율성과 확장가능한 멀티스레드 성능(효율적인 멀티스레드 성능)을 위해 설계되었고 이전 세대 그레이스몬트(Gracemont)에서 개선이 이루어진 코어다. P-코어는 코드명 레드우드 코브(Redwood Cove)로 기존 골든 코브(Golden Cove)를 개선한 코어로 싱글 및 멀티스레드 성능을 향상해 고성능을 목표로 한다. LP-E코어(Low Power Island E-Cores)는 저전력과 에너지 효율성(최고의 전력 효율)을 목표로 한다.
인텔은 타일 도입으로 컴퓨팅 코어 외에 성능에 영향이 적은 포베로스 3D 패키징과 SoC, 미디어, 그래픽 등은 다른 타일로 구성해 이전 세대 대비 전력 효율성을 크게 향상했다고 밝혔다. 링 패브릭(Ring Fabric)은 기존 세대와 같이 유지해 모든 타일을 상호 연결하여 칩 전체의 전력 및 지연 시간을 불리함을 최소화해준다.

E-코어는 IPC 향상에 더해 VNNI(벡터 신경망 명령어)와 ISA 등 AI 가속 향상, 향상된 분기 예측과 인텔 스레드 디렉터 피드백을 개선하고 세부적인 제어 및 최적화를 제공한다. 크레스트몬트 기반 E-코어는 그레이스몬트 대비 IPC 4~6% 개선, L1 캐시 64KB로 두 배, L2 캐시 4MB와 L3 캐시 3MB를 공유하는 2개 또는 4개 코어의 클러스터, 컴퓨트 타일에는 4코어 기반 E-코어 클러스터, SoC 타일에는 2코어 구성 E-코어 클러스터를 통합한다.

P-코어(레드우드 코브)의 IPC는 골든 코브(12세대 및 13세대)와 유사하며 L2 캐시와 코어당 대역폭 증가로 성능 및 처리 효율 개선, 성능 모니터링 유닛 개선으로 모니터링 향상 및 인텔 스레드 디렉터(Intel Thread Director)는 향상된 피드백을 통해 코어 성능을 최적화하고 워크로드(Workload)를 올바른 코어로 전달하는 데 도움을 준다.
인텔은 AVX2와 VNNI 포트 수를 2배로 늘려 개선했다고 했지만 정확한 수치는 공개되지 않았고 랩터 레이크(13세대)의 모든 CPU가 VNNI 명령어를 지원하지는 않았다. SoC 타일의 NPU가 AI 가속에 더 유용하겠지만 이러한 향상은 AI 애플리케이션을 사용하고 AI 기반 워크로드를 실행할 때 사용자 경험을 강화하도록 설계됐다. 다만 IPC 성능 향상에 대한 언급 외에 L4 캐시 탑재 여부, 코어 내 디코더 폭 등은 공개하지 않아 추후 공개를 통해 보다 상세한 내용을 알 수 있을 것으로 예상된다.
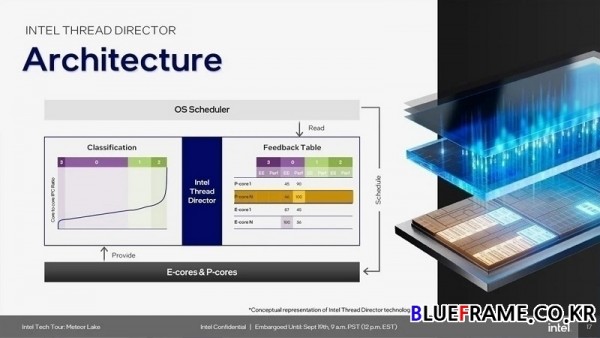

앨더레이크(12세대) 및 랩터레이크(13세대)의 인텔 스레드 디렉터는 스케줄링에 대한 미묘한 접근 방식을 도입했다. 12세대와 13세대 작업 처리에는 서비스 품질(QoS) 순위가 할당되었고 더 까다롭고 집약적인 작업 부하를 위해 더 높은 우선 순위의 작업이 P-코어에 할당되었으며 순위가 낮은 작업 부하는 주로 E-코어로 할당됐다. 메테오 레이크는 MS(Microsoft) 윈도우(Windows)와 협력해 새로운 개선 사항을 적용했다. SoC 타일 LP E-코어는 세 번째 서비스 계층으로 스레드 디렉터는 먼저 해당 계층에서 작업을 유지하려고 노력한다. 그 다음 스레드에 더 빠른 성능이 필요하면 컴퓨팅 타일로 이동해 더 빠른 고효율 E-코어와 고성능 P-코어에 액세스할 수 있다.
이는 전력 효율성 측면에서 전반적인 작업 부하 분산을 향상하며 매우 까다로운 작업은 더 높은 성능의 이점을 누릴 수 있는 P-코어로 주기적으로 이동해 스레드 스케줄링에 대한 동적 접근 방식을 제공한다. 이는 메테오 레이크의 전력 효율성을 향상시키도록 설계되어 작업 예약과 관련해 랩터 레이크(13세대)보다 더 많은 다양성을 제공하며 더 효율적이다. 특히 변동하는 워크로드(Workload)에 대한 신속한 조정이 필요한 시나리오와 SoC 내의 LP E-코어로 오프로드할 수 있는 가벼운 워크로드를 통해 더욱 효율적으로 작용한다.
컴퓨트 타일은 메테오 레이크의 모듈식 전원 관리 방식 덕분에 거의 즉각적으로 전원을 켜고 끌 수 있다. 마이그레이션이 완료되기 전 워크로드가 완료될 것으로 예상되는 경우 스케줄러가 작업을 이동하지 않도록 선택하는 등 인텔 스레드 디렉터는 작업이 실행될 것으로 예상되는 시간도 고려한다. 사용자 경험에 너무 자주 영향을 주지 않으면서 스레드를 LP E-코어에 성공적으로 배치할 수 있으면 이 방식은 많은 전력을 절약할 수 있게 된다. 인텔은 비디오 재생과 같은 시나리오에서 미디어 및 디스플레이 엔진과 함께 LP E-코어가 컴퓨트 타일로 넘어가지 않고도 시스템을 원활하게 실행할 수 있음을 보여주었다.

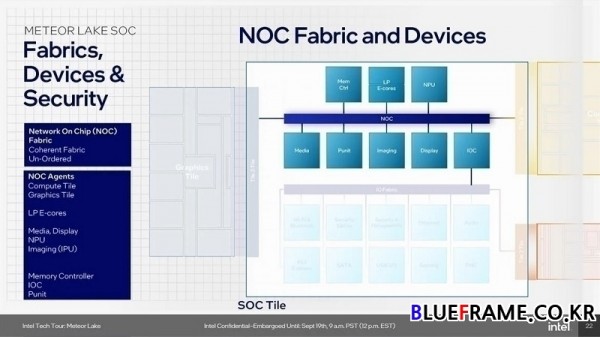
SoC 타일은 각 타일의 중심에 위치해 컴퓨팅, 그래픽 및 I/O 타일에 직접 연결되며 칩 세분화로 IP에 적합한 제조 공정을 자유롭게 사용할 수 있게 됐다. 컴퓨트 타일 및 그래픽스 타일 외의 다양한 연결 및 미디어/ 디스플레이 엔진 등의 주요 기능을 탑재한다.
고성능 디바이스를 연결하는 네트워크 온 칩(NOC, Network-on-Chip) 패브릭과 PCIe 기반 I/O 패브릭을 연결하는 IOC 브리지를 포함한다. 새로 추가된 NPU AI 엔진과 메모리 컨트롤러 & DDR 등을 탑재한다. I/O 타일은 SoC 타일의 I/O 패브릭을 확장하는 역할을 하며 두 타일 모두 TSMC N6 공정으로 제작된다. 타일에 따라 유연성을 제공하지만 최신 공정 노드의 이점을 크게 얻지 못하며 느린 발전 속도를 보일 수 있다.
전원 관리는 각 타일의 독립적인 기능을 지원하는 확장 가능한 전원 관리 시스템을 사용한다. 여러 PMC(전원 관리 컨트롤러)와 시스템 소프트웨어 간의 조정은 다양한 워크로드에 최적화되도록 설계되었으며 I/O와 같이 이전에 병목 현상이 발생했던 영역에서 에너지 효율성을 향상하고 대역폭을 확장하기 위해 새로운 확장 가능한 패브릭을 도입한다. SoC 타일의 중앙 PMC는 컴퓨트 타일 구성과 무관하며 고성능 디바이스를 연결한 NOC 패브릭은 지역 제어를 위한 로컬 전원 관리 장치(P-Unit)로 효율성을 향상한다.
SoC는 인텔 스레드 디렉터와 연관이 있는 새로운 LP E-코어를 포함했다. 컴퓨트 타일이 저전력 모드에 있거나 완전히 꺼져 있는 동안에도 활성 상태를 유지할 수 있도록 해 일반적인 사용 패턴에서 효율성을 크게 향상할 수 있게 된다.
I/O 패브릭은 PCI Express, Wi-Fi 6E & 7 및 블루투스(Bluetooth), 감지, USB 3/2, 이더넷, 전원 관리 컨트롤러(PMC) 및 보안 컨트롤러 등을 제공한다. 기존 컨버지드 보안 및 관리성 엔진(CSME)에서 실리콘 보안 엔진은 분리했다.

I/O 타일은 I/O 패브릭을 사용해 추가 PCI-E 및 USB4와 썬더볼트 4, I/O 타일을 컴퓨트 타일과는 나란히 배치해 SoC 타일의 표면적을 효과적으로 확장하며 이는 외부 연결의 복잡성을 줄이기 위한 배치다.

그래픽스(GPU) 타일은 인텔 아크(ARC) 그래픽(Xe-HPG)을 기반으로 하는 Xe-LPG 아키텍처를 적용한다. AMD와 엔비디아(NVIDA) 최신 GPU에 적용하는 TSMC N5(5nm) 공정에서 제작되며 12세대 Xe-LP 아키텍처 기반 Iris Xe 통합 그래픽 대비 와트당 성능이 약 2배 향상되었다. 미디어 엔진과 디스플레이 인터페이스는 SoC 타일로 분리됐다.
DirectX 12(DX12)에 최적화되었으며 OoOS(Out of Order Samplng)를 Xe-LPG에 도입했다. 실행 단위(EU, Execution Units)는 Xe 벡터 엔진으로 줄여서 XVE라고 하며 Xe-LPG 내에서 OoOS가 작동하는 방식은 공개되지 않았다.


Xe-LPG 아키텍처는 이전 세대 Xe-LP보다 더 많은 작업을 병렬로 처리할 수 있게 됐다. 2개의 렌더 슬라이스 사이에 128개의 벡터 엔진(Xe 코어당 12개)과 6개에서 8개로 늘어난 샘플러를 갖춘 8개의 Xe 그래픽 코어를 제공한다. Xe-LP 대비 1.33배 증가(32 XVE/EU 증가한 128개 XVE), 3 픽셀 백엔드(Pixel Backends)보다 향상된 4개의 픽셀 백엔드, 지오메트리 파이프라인 수를 2배인 2개, 인텔 통합 그래픽 라인업에 처음으로 8개의 전용 RTU(Ray Tracing Unit)도 도입했다. 통합 그래픽에서도 하드웨어 레이 트레이싱(Ray Tracing) 가속을 지원해 처리 성능을 향상한다. 셰이더 코어인 ALU(산술 논리 장치)는 Xe-LPG 코어당 ALU 128개인 1024개로 증가했으며 텍스처 맵핑 유닛(TMU)과 ROP 등 세부 정보는 공개되지 않았다.
버스 폭이 256비트(256bit) 벡터 엔진이 16개, 각 코어에는 192KB의 공유 L1 캐시, 각 벡터 엔진은 클럭당 64개의 INT8 연산을 지원하는 공유 FP64 실행 포트로 클럭당 16개의 FP32 연산과 클럭당 32개의 FP16 연산, 클럭당 2개의 확장 수학 연산 또는 클럭 단위당 단일 FP64 연산은 새로운 것으로 전력 효율성을 고려한 메테오 레이크의 설계 철학을 엿볼 수 있다. 벡터 엔진 쌍은 더 나은 효율성을 위해 동일한 단계로 실행될 수 있다. FP와 INT/EM이 분리되어 두 가지를 병렬로 사용하는 동시 발행 명령도 처리할 수 있으며 ARC GPU와 동일한 파이프라인 사용으로 소프트웨어 개발 속도가 빨라지고 전반적인 호환성과 안정성을 향상한다.
Xe-LPG는 모든 전압 지점에서 더 높은 클럭 속도를 제공해 전체 클럭은 더 높지만 최소 전압이 더 낮다. AI를 사용해 메테오 레이크의 타이밍 클로저를 미세 조정한 결과 20% 개선되었으며 TSMC N5 공정은 이를 구현 가능하게 해준다.


SoC 타일의 미디어 엔진과 디스플레이 엔진도 개선됐다. 미디어 엔진은 특정 코덱 가속을 위해 고정 기능 하드웨어를 제공하며 AVC, HEVC 및 AV1 디코딩과 인코딩을 모두 지원해 컨텐츠 제작의 활용성이 높아진다. AV1은 4:2:0 크로마 서브샘플링으로 10비트(10bit) 심도를 제공하며 HEVC는 필요한 경우 전체 10비트 4:4:4 크로마 서브샘플링을 제공할 수 있다.
미디어 엔진에는 각각 디코더와 인코더가 포함된 MFX 블록이 있다. 각 MFX 블록에는 비디오 스케일러와 색 공간 변환기, 엔진은 비디오 인핸서와 HDR 톤 매퍼, 베이어 프로세서를 공유한다. 디스플레이 엔진은 4개의 디스플레이 파이프를 제공하며 이 중 2개는 저전력에 최적화되었다. 인텔은 메모리 수요를 줄이기 위한 버스트 채우기, 반복되는 프레임에 대한 페치 및 생성을 건너뛰는 패널 자체 새로 고침(PSR) 등의 기술을 기반으로 리소스 수요를 더욱 줄여준다.

디스플레이 엔진은 HDMI 2.1과 DisplayPort 2.1과 eDP 1.4를 지원하며 최대 8K60 HDR과 4x 4K60 HDR, 1080p360 및 1440p360을 지원한다.
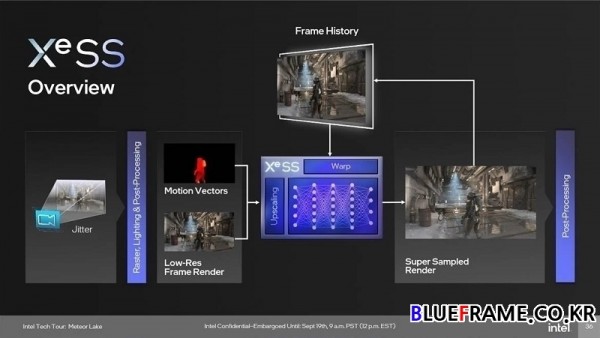
또한 불필요한 CPU 오버헤드는 줄이고 XeSS 업스케일링을 더해 에너지 소비를 줄이는데 중점을 두며 이를 통해 파이프라인의 렌더링 단계를 크게 단축한다. 앤티앨리어싱 단계는 AA+업스케일링으로 시간이 조금 더 소요되나 최종 포스트 프로세싱 효과를 변경하지 않으면서도 저해상도로 렌더링할 때 절약할 수 있는 시간에는 미치지 못한다.
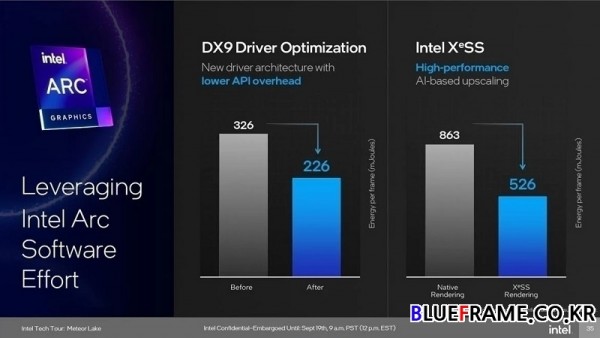
인텔은 최신 DX9 드라이버 최적화로 API 오버헤드를 31% 가량(프레임당 326m줄(mJoules)에서 프레임당 226m줄), XeSS 업스케일링은 네이티브 렌더링 시 40% 가량(프레임당 863m줄에서 526m줄) 감소했다. XeSS는 래스터, 조명 및 포스트 프로세싱을 통해 저해상도 프레임을 렌더링한 다음 모션 벡터를 적용해 고해상도 이미지를 합성한다. 프레임 히스토리에서 세부 정보를 피드백하여 향후 슈퍼 샘플링을 개선하고 추가 포스트 프로세싱을 적용해 화면에 표시되는 이미지를 개선한다.
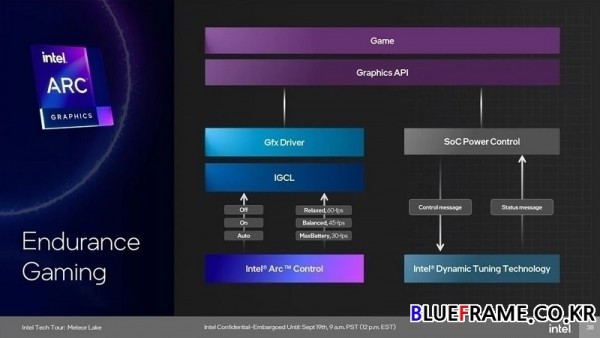
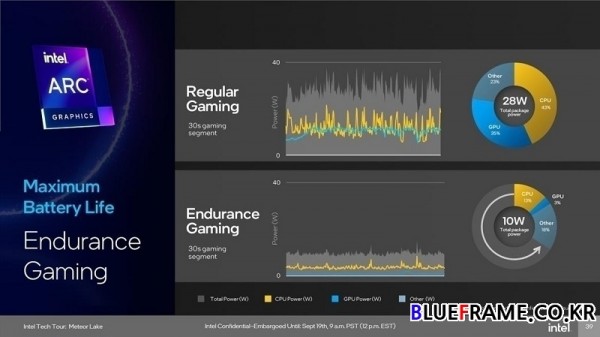
인듀어런스 게이밍도 추가되었으며 프레임 속도에 제약이 있지만 배터리 수명을 연장할 수 있다. 제어판에서 활성화 여부를 선택할 수 있고 60FPS/ 45FPS/ 30FPS를 목표로 하는 릴렉스, 밸런스, 맥스 배터리 등의 프리셋을 제공한다. 전체 전력 소비를 줄이는 것을 목표로 하며 10W에 불과한 SoC 전력 소모량으로 게임 플레이가 가능해지고 GPU는 약 1W만 소비한다.

메테오 레이크는 인텔 최초의 AI가 탑재된 소비자 CPU다. 인텔은 PC의 AI 적용은 제한적이나 훨씬 더 많은 잠재력에 무게를 두고 창의력 개선과 다양한 처리로 생산성을 향상한다.

메테오 레이크는 처음으로 전용 NPU를 탑재하고 있으나 이것이 AI의 전부는 아니다. NPU는 지속적인 AI 워크로드에 적합하며 많은 미디어 및 3D/ 렌더 파이프라인을 사용하는 생성형 AI는 여전히 GPU가 더 나은 선택이며 지연 시간이 짧은 단일 추론 요청을 반환하는 작업은 VNNI 및 기타 명령어를 제공하는 CPU로 충분하다. GPU를 사용하면 매우 빠른 결과를 반환 가능하지만 전력 사용량은 모든 CPU 접근 방식과 거의 비슷하며 NPU는 매우 효율적이지만 GPU만큼 빠르지 않다. 적당한 양의 에너지를 사용하면서 가장 빠른 결과는 하이브리드(GPU+NPU) 방식을 사용하는 것이다.
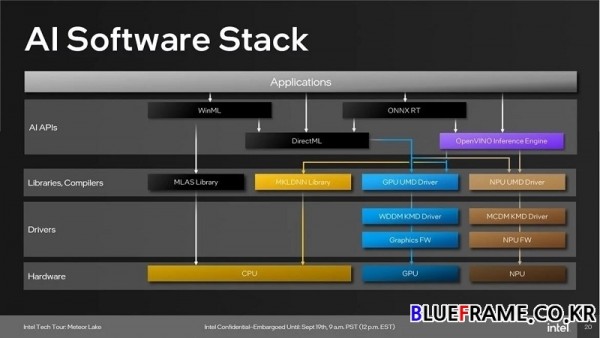
OpenVINO와 AI 소프트웨어 스택도 제공한다. 메테오 레이크의 AI 스택은 WinML, DirectML, ONNX RT 및 인텔 자체 OpenVINO를 포함한 다양한 API를 지원한다. 연결된 API는 서로 다른 IP를 활용하여 실행할 수 있는 다양한 라이브러리와 인터페이스를 제공한다. Adobe Creative Cloud는 GPU에서 실행되는 기능에 DirectML을 활용한다.
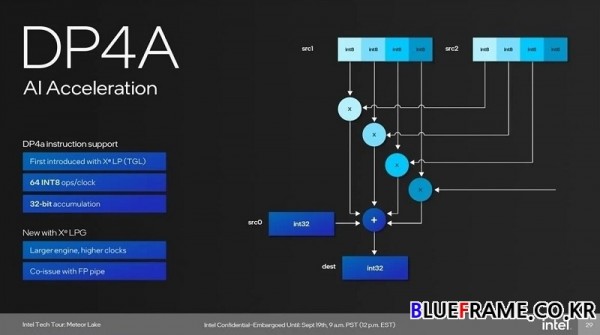
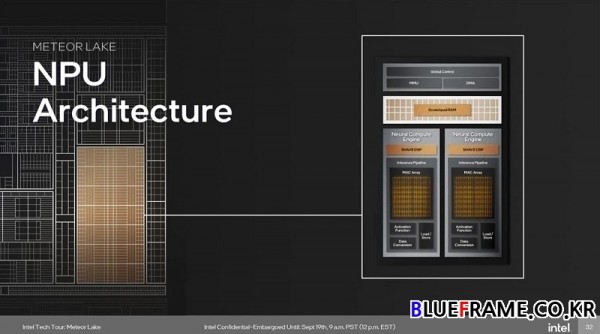
AI 가속을 위해서는 특정 명령어에 대한 지원이 필요하며 메테오 레이크 아키텍처에서는 하드웨어에서 AI 가속화를 지원한다. 타이거 레이크(Tiger Lake) Xe-LP에서 처음 도입된 INT8로 DP4A 명령어를 실행한다. 단일 32비트 정수를 INT8 레인으로 분할한 다음 클럭당 64개의 INT8 연산 속도로 계산하며 Xe-LPG는 더 큰 엔진과 더 높은 클럭, FP 파이프와 함께 명령어를 발행할 수 있다. NPU 아키텍처는 AI를 위해 특별히 설계되었으며 추론 파이프라인과 프로그래밍 가능한 스트리밍 하이브리드 아키텍처 벡터 엔진 디지털 신호 프로세서(SHAVE DSP)를 포함하는 두 개의 신경 컴퓨팅 엔진으로 설계되었다. DMA 엔진은 NPU를 통해 데이터의 흐름을 조정하는 역할을 하며 최대한의 성능을 추출하면서 효율성을 최적화한다.
인텔, intel, 인텔 이노베이션 2023, Intel Innovation 2023, 차세대, 프로세서, CPU, 메테오 레이크, Meteor Lake, 아키텍처, 공개










