

PC | 최대 4배 빨라진 3세대 RTX, 엔비디아 지포스 RTX 4090·RTX 4080 발표
엔비디아(NVIDIA) 9월 21일(현지시간) GTC 2022 키노트 지포스 비욘드 스페셜 브로트캐스트(GeForce Beyond : A Special Broadcast)를 통해 3세대 RTX 에이다 러브레이스(Ada Lovelace) 아키텍처를 기반으로 하는 차세대 지포스 RTX 40 시리즈(GeForce RTX 40 Series)인 지포스 RTX 4090(GeForce RTX 4090)과 지포스 RTX 4080(GeForce RTX 4080)을 공개했다.
차세대 지포스 RTX 40 시리즈(GeForce RTX 40 Series)인 지포스 RTX 4090(GeForce RTX 4090)과 지포스 RTX 4080(GeForce RTX 4080)는 새로운 아키텍처를 기반으로 기존 지포스 RTX 30 시리즈를 전환한다.
이번 지포스 RTX 40 시리즈에 대해 엔비디아 젠슨 황 CEO는 RTX 뉴럴 렌더링의 새로운 시대를 여는 제품이라고 소개하며 3세대 RTX로 이전 세대 대비 향상된 성능과 전력 효율을 제공할 것이라고 밝혔다.

엔비디아는 거의 25년 전 프로그래밍 가능한 고급 음영 처리 GPU를 도입했으며 GPU는 3D 그래픽에 혁명을 일으켰고 아티스트를위한 무한한 팔레트가 있는 매체를 만들었다. 시그라프 2018(Siggraph 2018)에서 두 개의 새로운 프로세서로 프로그래밍 가능한 셰이더를 확장한 NVIDIA RTX를 출시한 바 있다.
엔비디아 RTX의 RT 코어는 실시간 레이 트레이싱을 가속하며 텐서 코어(Tensor Core)는 딥 러닝의 핵심인 행렬 연산을 처리한다. RTX는 컴퓨터 과학자들에게 새로운 지평을 열었고 수많은 새로운 알고리즘이 등장했다. 이제 엔비디아는 RTX 뉴럴 렌더링의 새로운 시대가 시작되었다고 밝히며 3세대 RTX인 에이다 러브레이스(Ada Lovelace) 아키텍처를 발표했다. GPU 아키텍처 코드명인 에이다 러브레이스는 세계 최초의 컴퓨터 프로그래머이자 수학자인 Ada Loverlace에서 가져왔다.

에이다 러브레이스(Ada Lovelace) 아키텍처 기반의 GPU는 TSMC 4N 프로세서로 제조되고 아키텍처 개선을 바탕으로 전력 효율성이 최대 2배 향상된다. 760억 개의 트랜지스터와 608mm^2 다이 사이즈, 암페어(Ampere) 세대 대비 70% 더 많은 18,000개 이상의 쿠다(CUDA Cores)를 통합했다. 3세대 RT 코어(Gen3. RT Core)와 4세대 텐서 코어(Gen 4. Tensor Core)이를 통해 세 가지의 RTX 프로세스를 향상해 이전 세대 대비 최대 4배의 향상을 이루어냈다.
또한 이전 세대의 2배 이상인 최대 83테라플롭스의 세이더 성능, 3세대 RT 코어는 이전 세대보다 2.8배 증가, 최대 191개의 유효 레이 트레이싱 테라플롭스 처리, 4세대 텐서 코어의 FP8 가속은 이전 세대보다 5배 증가, 최대 1.32 텐서 페타플롭스의 연산 성능을 제공한다.
또 셰이더 엑시큐션 리오더링(SER, Shader Execution Reordering)은 세이딩 워크로드를 즉시 재조정해 GPU 리소스를 더 잘 활용해 실행 효율성을 향상한다. CPU에 대한 비순차적 실행만큼 중요한 혁신으로 알려진 SER은 레이 트레이싱 성능을 최대 3배, 게임 내 프레임 속도를 최대 25% 향상시킨다. 2배 더 빠른 성능을 제공하는 에이다 옵티컬 엑셀러레이터(Ada Optical Flow Accelerator)를 통해 DLSS 3(Deep Learning Super Sampling 3)는 장면의 움직임을 예측해 신경망이 이미지 품질을 유지하면서 프레임률을 높일 수 있도록 해준다.
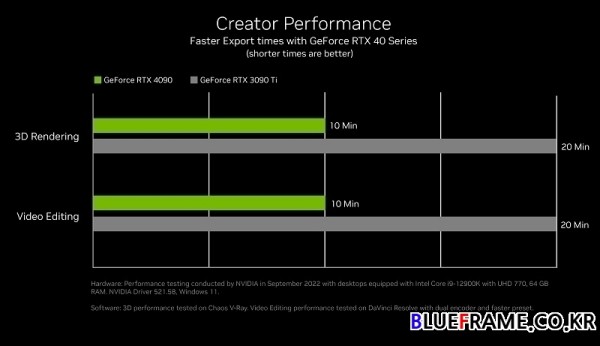
듀얼 엔비디아 인코더(NVENC)는 엑스포트 시간을 최대 절반으로 단축해주며 이전 지포스 RTX 30 시리즈는 AV1 디코딩만을 지원했으나 지포스 RTX 40 시리즈는 AV1 인코딩과 디코딩을 모두 지원한다. NVENC AV1 인코딩은 OBS, 블랙매직 디자인 다빈치 리졸브(Blackmagic Design DaVinci Resolve), Discord(디스코드) 등에서 지원한다.
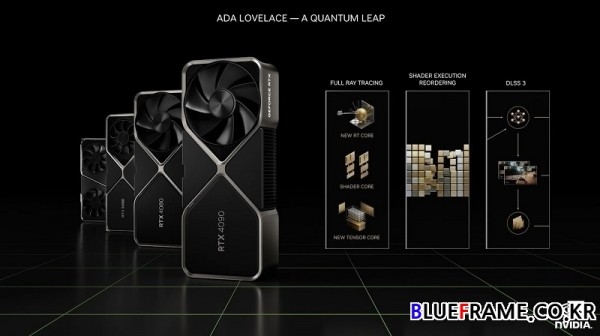
에이더 러브레이스 아키텍는 쉐이더 실행 순서 재배치(SER, Shader Execution Reordering)와 새로운 3세대 RT 코어, 새로운 4세대 텐서 코어를 기반으로 세 가지 RTX 프로세스 향상을 이루어냈다.
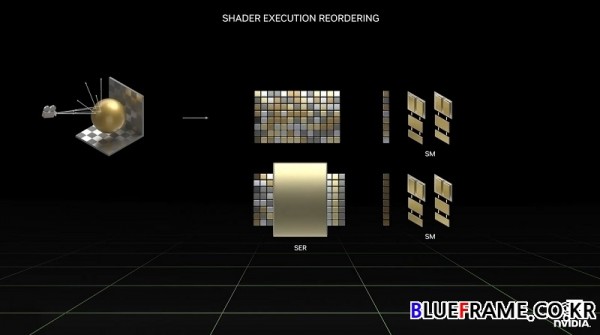
Ada는 이전 세대 보다 2배 증가한 90테라플롭스의 새로운 스트리밍 멀티프로세서로 SM에는 쉐이더 실행 순서 재배치(SER, Shader Execution Reordering) 기술 포함, 즉석에서 작업을 재조정하여 레이 트레이싱 속도를 2-3배 높인다. SER은 CPU의 비순차적 실행만큼이나 혁신적인 기술이다.
2배의 레이 트라이앵글 교차 처리량, 2개의 새 하드웨어 유닛이 있는 새로운 RT 코어, 새로운 불투명도 마이크로맵 엔진은 알파 테스트 지오메트리의 레이 트레이싱 속도를 2배 높인다. 새로운 마이크로 메쉬 엔진은 BVH 빌드 및 스토리지 비용 없이 지오메트리의 풍요로움을 높여준다.
호퍼(Hopper) FP8 트랜스포머 엔진과 1.4페트플롭스(1.4Petaflops) 텐서(Tensor) 처리를 갖춘 새로운 텐서 코어를 탑재한다.
높은 프레임 속도를 보장하기에는 원시 레이 트레이싱의 힘이 충분하지 않다. 레이 트레이싱에서는 빛이 사방으로 반사되고 다양한 유형의 표면을 교차하기 때문에 병렬화가 어렵기로 악명이 높다. 유사한 작업을 동시에 처리할 때 GPU는 매우 병렬적이고 가장 효율적이며 레이 트레이싱 워크로드에서는 여러 스레드가 서로 다른 쉐이더를 처리하거나 결합 또는 캐시가 어려운 메모리에 액세스하게 된다. 쉐이더 실행 순서 재배치(SER)는 GPU의 리소스를 더 잘 활용할 수 있도록 고급 음영 처리 워크로드를 즉석에서 재조정하여 실행 효율성을 개선한다. 이를 통해 레이 트레이싱은 2-3배 증가했고 전체 게임 성능이 25% 향상되었다.

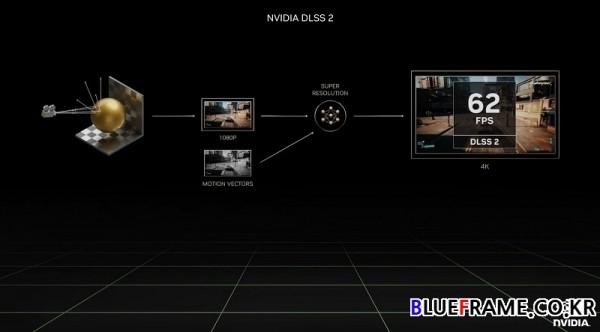
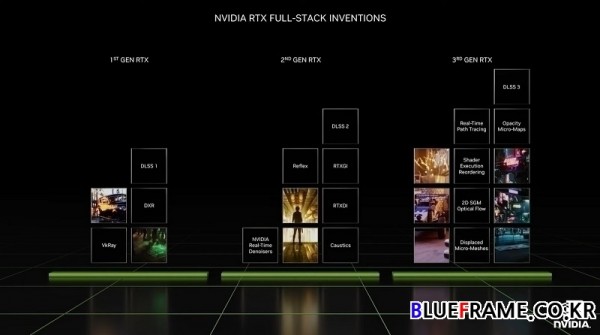
가속 컴퓨팅과 마찬가지로 컴퓨터 그래픽스 분야는 풀 스택의 과제다. 획기적인 발전을 위해서는 알고리즘 뿐만 아니라 아키텍처와 디자인의 혁신까지 필요하다. 예를 들어 엔비디아의 RTXGI(RTX Full-Stack Inventions)는 레이 트레이싱을 사용해 실시간으로 멀티 바운스 간접광을 처리한다. RTXDI는 레이 트레이싱을 사용하여 수백만 개의 광원에서 나오는 직접 조명을 처리하고 모든 조명에서 그림자를 드리운다. RTXDI는 광고판, TV 스크린, 네온 튜브와 같은 방사 표면에 사용된다. NRD(NVIDIA Real-Time Denoisers)는 불완전한 레이 트레이싱된 이미지로 실측 정보를 추론하여 필요한 레이의 수를 줄이는 시공간 노이즈 제거 기술이다.
DLSS(Deep Learning Super Resolution)는 엔비디아의 성과 중 하나다. 레이 트레이싱에는 엄청난 양의 연산이 필요하다. CGI 무비의 각 프레임은 렌더링하는 데 몇 시간이 걸린다. 엔비디아는 이를 실시간으로 구현하고자 한다.
NVIDIA RTX는 실시간 레이 트레이싱의 세계를 열였다. RT 코어는 BVH 횡단 및 레이 트라이앵글 교차 테스트를 수행하므로 SM이 각 레이에 수천 개의 명령을 소비하지 않도록 할 수 있다. 하지만 RT 코어의 경우에도 게임에서는 프레임 속도가 너무 낮았다. 또 다른 돌파구가 필요했으며 바로 딥 러닝을 이용하는 것이다.
DLSS는 컨볼루셔널 오토인코더 AI 모델을 사용하며 저해상도의 현재 프레임과 고해상도의 이전 프레임을 이용해 픽셀 대 픽셀 기반으로 더 높은 해상도의 현재 프레임을 예측한다. AI 모델은 초고해상도 16K 참조 이미지를 예측하도록 트레이닝 되었다. 예측된 이미지와 참조 이미지의 차이는 신경망을 트레이닝하는 데 사용된다. 이 프로세스는 네트워크가 고품질 이미지를 예측할 수 있을 때까지 수만 번 반복된다.
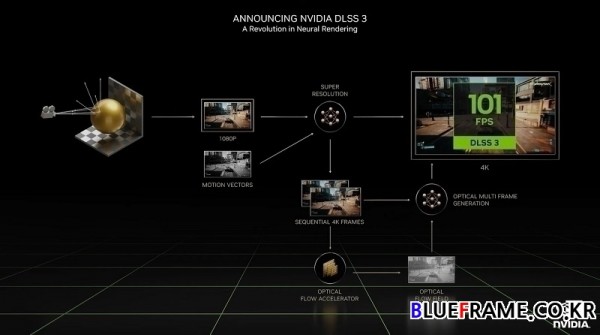
Ada는 픽셀 단위가 아닌 완전히 새로운 프레임을 생성하는 새로운 AI인 DLSS 3를 도입했다. DLSS 3에는 새로운 광학 흐름 가속기, 게임 엔진 모션 벡터, 컨볼루셔널 오토인코더 AI 프레임 생성기 및 Reflex 초저지연 파이프라인의 네 가지 구성 요소가 있다.
DLSS 3은 장면이 어떻게 변화하고 있는지 알아보기 위해 새 프레임과 이전 프레임을 처리한다. 광학 흐름 가속기(Optical Flow Accelerator)는 뉴럴 네트워크에 프레임별 픽셀의 방향과 속도를 제공한다. 그런 다음 게임의 프레임 쌍을 지오메트리 및 픽셀 모션 벡터와 함께 뉴럴 네트워크에 제공하여 중간 프레임을 생성한다. DLSS 3는 그래픽 파이프라인을 처리하지 않고 완전히 새로운 프레임을 생성하여 강력한 렌더링보다 게임 성능을 최대 4배나 향상시킨다.
DLSS 3는 게임에 관여하지 않고 새 프레임을 생성하므로 GPU와 CPU에 제한된 게임 모두에 이점을 제공한다. 물리효과가 많거나 월드가 대규모인 CPU 제한 게임의 경우, DLSS 3를 사용하면 Ada GPU는 CPU가 게임을 컴퓨팅하는 것보다 훨씬 높은 프레임 레이트로 게임을 렌더링할 수 있다. DLSS3는 엔비디아의 가장 뛰어난 뉴럴 렌더링의 하나다.



SER 및 DLSS3를 지원하는 새로운 최대 레이 트레이싱 모드로 표시되는 사이버펑크 2077(Cyberpunk 2077) 데모를 통해 지포스 RTX 30 시리즈와 지포스 RTX 40 시리즈의 DLSS 3와 RTX On 성능을 비교했다.
최첨단 그래픽을 미래로 나아가게 하려면 엄청난 양의 컴퓨팅 성능이 필요하다. 사이버펑크와 같은 최신 게임에서는 조명 효과만을 위해 모든 필셀에 대해 600개 이상의 레이 트레이싱 연산을 실행한다. 이는 4년 전에 실시간 레이 트레이싱을 처음 도입했을 때에 비해 16배 증가한 것이다. 하지만 이러한 연산을 위해 GPU에서 사용할 수 있는 트랜지스터의 수는 이 같은 속도로 증가하지 않았다. 이것이 RTX의 힘이다. AI를 통해 4년 만에 16배 향상된 성능을 제공할 수 있다. 일부 픽셀은 계산되지만 대부분은 예측된다.

사실적인 물리효과와 거대한 세계로 인해 CPU로 한정된 게임인 Microsoft Flight Simulator 데모도 시연이 이루어졌다. DLSS 3와 RTX On/ Off 프레임 비교로 지포스 RTX 40은 지포스 RTX 30 대비 2배 가량 높은 프레임을 제공했다.



NVIDIA Lightspeed Studio는 옴니버스(Omniverse)를 사용해 역사상 대단히 유명한 게임 중 하나를 포탈(Portal)을 리마스터링했다. 포탈(Portal)은 밸브(Valve)가 개발하여 2007년에 출시되었다. GDC의 올해의 게임에 선정됐고 Smithsonian에 전시되었다. Portal RTX는 향수를 불러일으키는 동시에 미래적인 분위기를 제시하며 포탈 소유자에게 11월 Free DLC로 제공할 예정이다.
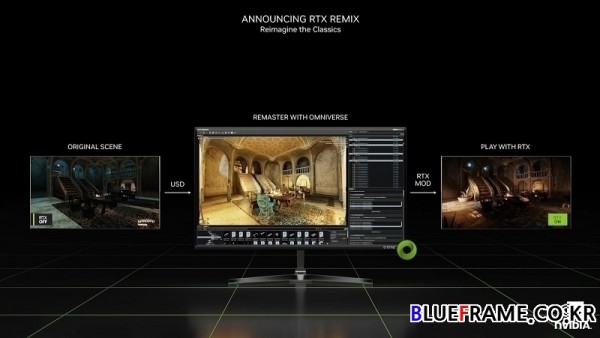


가장 인기는 10대 경쟁 게임 중 9개에서는 모드가 아주 중요하다. 엔비디아는 게임 모딩을 위해 RTX Remix라는 옴니버스 애플리케이션을 만들었다. 게임을 시작하고 옴니버스에 로드되는 USD로 게임을 캡처한다. 포탈 RTX는 모드로 옴니버스로 만들어졌다. 역대 최고의 모드 게임 중 하나인 Bethesda의 Elder Scrolls Morrowind를 데모로 소개했다. RTX Remix의 AI 지원 툴세트에는 텍스처 및 에셋 해상도 향상을 위한 딥 러닝 모델과 물리적으로 정확한 특성을 갖도로 재료를 변환하는 AI 모델을 제공한다.
옴니버스의 풍부한 크리에이티브 도구 에코시스템을 사용하여 게임 에셋을 개선할 수 있으며 완료되면 RTX 모드 팩을 내보내고 RTX 렌더러로 게임을 플레이한다. RTX Remix는 놀라운 기술이며 지금까지 만들어진 것 중 가장 발전된 게임 모딩 도구다. Portal RTX와 RTX Remix는 Ada 출시 직후 사용할 수 있다.
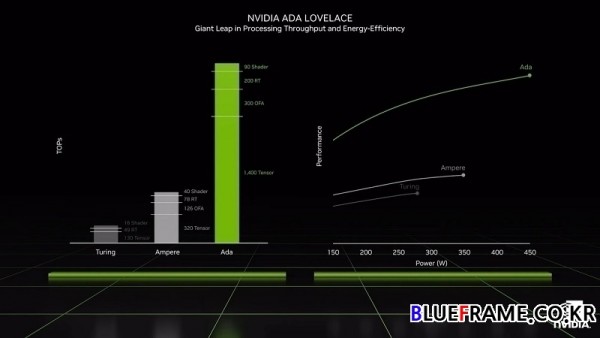
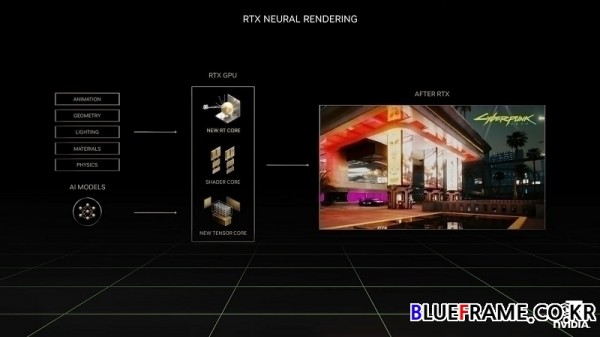
RTX 뉴럴 렌더링 알고리즘은 프로그래밍 가능한 쉐이더, RT 코어 및 텐서 코어에서 실행되는 놀라운 이미지를 생성한다. Ada의 총 처리 처리량은 암페어 세대 대비 엄청난 도약이며 실제 성능이 이를 뒷받침한다. 래스터화된 게임에서 Ada는 최대 2배 빠르며 레이 트레이싱 게임에서는 4배 더 빠르다. Ada는 놀라운 정도로 에너지 효율적이며 암페어 대비 동일한 전력에서 2배 이상의 성능을 발휘한다. 그리고 Ada를 한계까지 밀어붙일 수 있다. 엔비디아는 실험실에서 3GHz 이상으로 Ada를 오버클럭했다.
RTX는 그래픽을 재창조했으며 이제 Ada는 RacerX와 같은 미래의 게임을 완전히 시뮬레이션할 수 있는 길을 닦고 있다. Ada Lovelace 세대는 뉴럴 렌더링의 엔진인 세 개의 RTX 프로세서를 모두 향상시킨다. Ada는 게이머를 위한 비약적인 도약이며 옴니버스와 같이 완전히 시뮬레이션된 세계의 크리에이터들을 위한 길을 마련해준다.
지포스 RTX 4090과 지포스 RTX 4080
엔비디아는 에이다 러브레이스(Ada Lovelace) 아키텍처 기반의 지포스 RTX 40 시리즈 지포스 RTX 4090과 지포스 RTX 4080의 2종을 우선 공개했다.

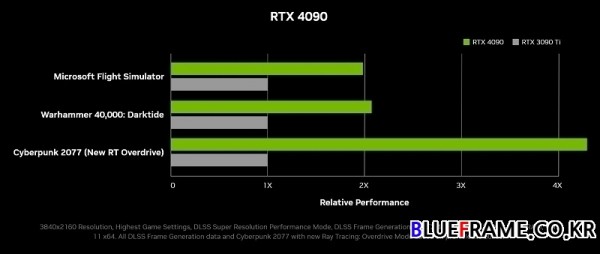

새로운 헤비급 챔피언이자 세계에서 가장 빠른 게임용 GPU로 소개된 지포스 RTX 4090은 16,384개의 쿠다 코어, 24GB의 고속 마이크론(Micron) GDDR6X 메모리, 지포스 RTX 3090 Ti(GeForce RTX 3090 Ti)보다 최대 2-4배(2X-4X) 빠르며 가격은 1599달러($1599, 222만 9천원 선), 2022년 10월(October) 12일 출시한다.
쉐이더 실행 순서 재배치가 있는 새로운 SM, 불투명도 마이크로맵 및 마이크로 메쉬 엔진을 갖춘 새로운 RT 코어, FP8 트랜스포머 엔진을 탑재한 새 텐서 코어, DLSS 3를 위한 픽셀 처리 300TOPS 광학 흐름 가속기를 제공한다. 전반적으로 처리량이 4배 늘어난다. 현재 세계에서 가장 강력한 GPU 챔피언인 3090 Ti와 비교하면 RTX 4090이 MS 플라이트 시뮬레이터에서 2배 더 빠르고 Portal RTX에서는 3배 빠르며 RacerX에서는 4배 빠르다.
풀 레이 트레이싱 게임에서 DLSS 3가 포함된 RTX 4090은 DLSS 2를 탑재한 이전 세대의 RTX 3090 Ti에 비해 최대 4배 더 빠르며 동일한 450W 전력 소비를 유지하면서 게임에서 최대 2배 더 빠르다. 4K 해상도 게임에서 지속적으로 초당 100프레임 이상을 제공한다.


지포스 RTX 4080은 16GB GDDR6X와 12GB GDDR6X 2가지 버전으로 출시된다. 지포스 RTX 3080 Ti(GeForce RTX 3080 Ti)보다 2-4배(2X-4X) 빠르며 RacerX에서 3080 Ti 대비 3배의 성능을 제공한다. 가격은 16GB 버전이 1199달러($1199, 167만 2천원 선), 12GB 버전은 899달러($899, 125만 3천원 선), 2022년 11월(November) 중으로 출시 예정이다.
RTX 4080 16GB는 9,728개의 쿠다 코어와 16GB의 고속 마이크론 GDDR6X 메모리, DLSS 3로 지포스 RTX 3080 Ti보다 2배 빠르며 더 낮은 전력에서 지포스 RTX 3090 Ti보다 강력하다. RTX 4080 12GB는 7,680개의 쿠다 코어와 12GB의 마이크론 GDDR6X 메모리, DLSS 3로 이전 세대 플래그십 GPU인 RTX 3090 Ti보다 빠르다.

엔비디아는 329달러($329, 45만 8천원 선)부터 시작하는 지포스 RTX 3060/ 3070/ 3080의 지포스 RTX 30 시리즈와 899달러($899, 125만 3천원 선)부터 시작하는 지포스 RTX 40 시리즈인 지포스 RTX 4080 12GB/ 16GB/ RTX 4090의 라인업을 함께 유지한다. 지포스 RTX 30 시리즈는 주류 게이머들, 지포스 RTX 40 시리즈는 열정적인 게이머들에게 궁국의 성능을 제공한다.

한편 엔비디아 지포스 RTX 4090과 지포스 RTX 4080 GPU는 에이수스(ASUS), 컬러풀(Colorful), 게인워드(Gainward), 갤럭시(Galaxy), 기가바이트(GIGABYTE), 이노비전 3D (Innovision 3D), MSI, 팰릿(Palit), PNY, 조텍(Zotac) 등 상위 애드인 카드 제조사를 통해 기본 및 팩토리 오버클럭(OC) 제품이 출시된다.
국내에서는 갤럭시코리아(Galax 브랜드), 디앤디컴(Gainward 브랜드), 아이노비아(Inno3D 브랜드), 에스티컴(Palit 브랜드), 엠에스아이코리아(MSI 브랜드), 웨이코스(Colorful, Manli 브랜드), 이엠텍(EMTEK 브랜드), 인텍앤컴퍼니(ASUS 브랜드), 제이씨현시스템(Gigabyte, PNY 브랜드), 조텍코리아(Zotac 브랜드), 피씨디렉트(Gigabyte 브랜드), 한미마이크로닉스(PNY 브랜드) 등 엔비디아 국내 공식 파트너사를 통해서 공급 예정이다.


또한 엔비디아 지포스 RTX 4090과 지포스 RTX 4080(16GB)는 엔비디아 자체 설계를 원하는 팬을 위해 제한된 파운더스 에디션(Founders Editions)으로 엔비디아에서 직접 생산된다. 지포스 RTX 4090은 2,630,000원부터 시작, RTX 4080 16GB는 1,920,000원부터 시작, RTX 4080 12GB는 1,400,000원부터 시작한다.
지포스 RTX 40 시리즈는 에이서(Acer), 에일리언웨어(Alienware), 에이수스, 델(Dell), HP, 레노버(Lenovo) 및 MSI 등 전 세계 시스템 제조사들의 게임 시스템에 탑재된다.
엔비디아, NVIDIA, 차세대, 에이다 러브레이스, Ada Lovelace, GPU 아키텍처, 아키텍처, 3세대, RTX, 지포스 RTX 40 시리즈, 지포스 RTX 4090, GeForce RTX 4090, 지포스 RTX 4080, GeForce RTX 4080, 공개, 발표, 10월 12일, 출시, 11월









