

서버 | 인텔 Xe-HPC 마이크로 아키텍처, 폰테베키오(Ponte Vecchio)
인텔은 8월 19일(현지시간) 인텔 아키텍처 데이 2021(Intel Architecture Day 2021)을 개최하고 Xe 고성능 컴퓨팅(Xe HPC) 아키텍처와 이를 기반으로 하는 폰테베키오(Ponte Vecchio)를 공개했다.
인텔은 이번 행사에서 새로운 두 개의 x86 코어 아키텍처와 인텔 쓰레드 디렉터 워크로드 스케줄러를 탑재한 인텔 최초의 퍼포먼스 하이브리드 아키텍처의 앨더레이크, 데이터센터용 차세대 인텔 제온 스케일러블 프로세서인 사파이어 래피즈, 인프라 처리 장치(IPU), 그래픽 아키텍처 제품군으로 Xe HPG와 Xe HPC 아키텍처, 알케미스트와 폰테배키오 시스템-온-칩(SoC) 등 다양한 기술을 발표했다.


인텔 Xe 고성능컴퓨팅(Xe HPC) 기반의 폰테베키오(Ponte Vecchio)는 인텔의 SoC 중 가장 복잡하면서 가장 성공적인 IDM 2.0 전략 사례로 여러 첨단 반도체 공정, 혁신적인 EMIB 멀티 다이 인터커넥트 기술 및 포베로스 3D 패키징을 활용했다.
인텔은 폰테베키오로 업계 최고의 FLOP와 컴퓨팅 밀도를 제공해 인공지능, 고성능컴퓨팅(HPC) 및 고급 분석 워크로드를 가속화하는 1,000억개의 트랜지스터를 탑재했다. 이를 통해 Xe HPC 마이크로아키텍처를 기반으로 업계 선도 FLOP와 컴퓨팅 밀도를 제공하여 AI, HPC, 고급 분석 워크로드를 가속화한다.

인텔은 아키텍처 데이 2021에서 폰테베키오가 유명 AI벤치마트 기준 추론과 학습 모두에서 업계 기록을 갱신할만한 초기 폰테 베키오 실리콘의 성능을 공개했다. 인텔의 A0 실리콘 성능으로 45 TFLOPS FP32 처리량 이상, 메모리 패브릭 대역폭 5TBps 이상, 연결 대역폭 2TBps 이상을 제공하고 있다고 밝혔다. 인텔은 또한 4만 3천 개 이상의 초당 이미지 레스넷 추론 성능 및 레스넷 학습에서 3천 4백 개 이상의 초당 이미지를 보여주는 데모를 공유했다.

폰테 베키오는 타일로 표현되는 여러 가지 복잡한 디자인으로 구성되어 있으며 타일 사이에 저전력, 고속 연결을 가능하게 하는 EMIB 타일을 통해 조립된다. 이들은 포베로스(Foveros) 패키지에 함께 담겨 전력 및 상호 연결 밀도를 위해 활성 실리콘을 3D 적층한다. 고속 MDFI 인터커넥트를 통해 스택을 1개에서 2개로 확장할 수 있다.

폰테 베키오는 인텔은 Xe -코어 당 8개의 벡터 및 매트릭스 엔진(XMX – Xe Matrix eXtensions), 슬라이스 및 스택 정보, 컴퓨팅, 베이스, Xe 링크 타일용 프로세스 노드 등 Xe HPC 마이크로 아키텍처의 IP 블록 등으로 구성된다.


컴퓨트 타일(Compute Tile)은 Xe 코어의 밀도 높은 패키지이며 폰테 베키오의 심장이며 TSMC의 가장 향상된 공정 기술인 N5(5nm FinFET)를 기반으로 한다. 하나의 타일엔 8개의 Xe 코어가 있으며 총 4MB L1 캐쉬로 전력 효율적인 컴퓨팅을 제공한다. 인텔은 설계 인프라 구성 및 도구 흐름과 이 공정기술에 대한 타일을 테스트하고 검증할 수 있는 방법론을 통해 기반을 다졌다.

Xe-HPC는 컴퓨트 타일과 베이스 타일로 구성되며 슬라이스(Slice)를 기본으로 스택을 확장한다. 16 Xe-코어와 L1 8MB 캐쉬, 16 레이 트레이싱 유닛, 1 하드웨어 컨텍스트(1 Hardware Context)로 구성된다.
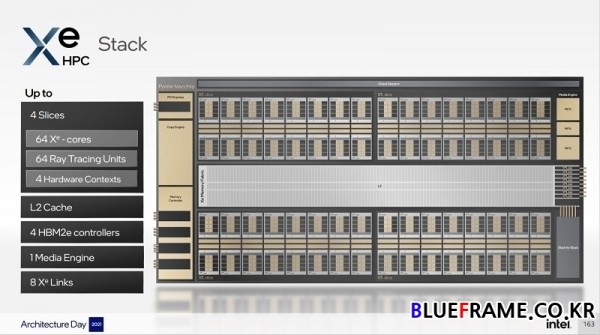

슬라이스 구성에 따라 1 스택(1 Stack)과 2 스택(2 Stack)을 지원한다. Xe HPC 1 스택(1 Stack)은 최대 4 슬라이스(Slice)로 64 Xe-코어와 64 레이 트레이싱 유닛, 4 하드웨어 컨텍스트(4 Hardware Context), L2 캐쉬, 4 HMB2e 컨트롤러, 1 미디어 엔진(Media Engine), 8 Xe-Links로 구성된다.
2 스택은 8 슬라이스로 128 Xe- 코어와 128 레이 트레이싱 유닛, 8 하드웨어 컨텍스트(8 Hardware Context), 8 HMB2e 컨트롤러, 2 미디어 엔진(2 Media Engines), 16 Xe-Links를 제공한다. Xe-코어 컴퓨팅 성능은 벡터 엔진(ops/clk)는 256 FP32, 256 FP64, 512 FP16 연상 성능, 매트릭스 엔진(ops/clk)은 2048 TF32, 4096 FP16, 4096 BF16, 8192 INT8(정수 연산) 성능을 각각 제공하는데 Xe-HPG의 Xe-코어는 전문적인 컴퓨팅 연산 성능 보다는 게이밍에 최적화된 만큼 이와 처리 성능 및 지원에 차이를 보일 수 있다.
Xe-HPC(Xe-High Performance Computing) Xe-코어는 게이밍을 타겟으로 하는 Xe HPG의 Xe-코어 구성과 차이를 보인다. Xe HPG의 Xe-코어는 256bit 16 벡터 엔진과 1024bit 16 매트릭스 엔진을 기반으로 구성하는데 반해 Xe-HPC의 Xe-코어는 512bit 8 벡터 엔진과 4096bit 매트릭스 엔진으로 구성된다.
Xe-HPC는 Xe-HPG 대비 각각 절반인 8개의 벡터 및 매트릭스 엔진을 제공한다. 이는 Xe-HPG가 게이밍을 위해 벡터와 매트릭스 엔진을 코어 당 늘려 연산 효율을 높인 구조인 반면 Xe-HPC는 고성능 컴퓨팅으로 높은 컴퓨팅 연산을 필요로 하는 전문적인 분야에의 최적화를 위해 더 넓은 대여폭을 제공하는 백터와 매트릭스 엔진으로 구성됐다. Xe-HPC는 로드/스토어(Load/ Store) 512B/CLK, 캐쉬 L1$/ SLM(512KB), I$로 구성되는데 Xe-HPC는 게이밍에 보다 최적화된 캐쉬 구조를 제공할 것으로 예상된다.
이전에 공개된 Xe-HPC의 GPU 타일(Tile)에서 512개 실행유닛(512EUs, 4096코어), 2타일 1024개 실행유닛으로 8192코어, 4타일은 2048개 실행유닛으로 16384 코어 구성으로 보면 Xe-HPG는 512개 실행 유닛으로 4096코어를 이용하고 라인업에 따라 다양한 구성이 가능해진다. 또 Xe-HP 단일 타일은 4K 60 HEVC 컨텐츠 10개의 개별 스트림을 트랜스코딩할 수 있는 성능으로 4타일은 40개의 다른 스트림을 트랜스코딩할 수 있으며 MCM GPU로 1.3GHz 클럭에서 FP32 42 TFLOPs 연산 성능을 제공하는 것으로 알려진 바 있다.

컴퓨트 타일은 포베로스와 함께 3D 스택을 위한 매우 조밀한 36마이크론 범프 피치를 갖추고 있다. 베이스 타일(Base Tile)은 폰테 베키오의 결합 조직이다. 포베로스 기술에 최적화된 인텔7(Intel 7) 공정 기반의 대형 다이이다. 640mm^2 사이즈, L2 캐쉬 144MB를 제공한다.
베이스 타일은 복잡한 IO 및 고대역폭 구성요소와 SOC 인프라(PCIe Gen5, HBM2e 메모리, 타일 간 연결을 위한 MDFI 링크, EMIB 브리지 연결)를 포함한다. 높은 2D 인터커넥트와 짧은 지연 시간으로 초고대역폭 3D 연결을 통해 무한 연결 시스템을 구현하며 인텔 기술 개발 팀은 대역폭, 범프 피치, 신호 무결성에 대한 요구사항을 충족하기 위해 노력했다.


Xe 링크 타일(X e Link Tile)은 GPU 간 연결을 제공하며 타일 당 8개의 링크를 지원해 최대 8GPU를 연결 가능한 확장성을 제공한다. 이를 통해 고성능 컴퓨팅 연산을 필요로 하는 분야에서 효율성을 높일 수 있다.

HPC와 AI의 확장을 위한 필수 요소로 인텔에서 지원되는 가장 빠른 Serdes(최대 90G)를 목표로 한다. 이 타일은 오로라(Aurora) 엑사스케일 슈퍼컴퓨터의 스케일업 솔루션을 활성화하기 위해 추가되었다.

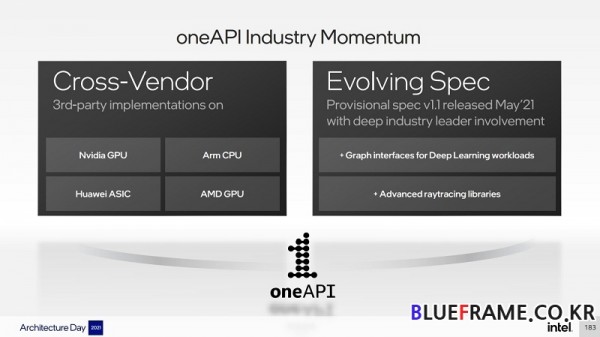
폰테베키오는 Xe 아키텍처와 마찬가지로 개방형 표준 기반 크로스 아키텍처 및 크로스 벤더 통합 소프트웨어 스택인 oneAPI를 통해 제공된다.
oneAPI는 크로스 아키텍처 및 크로스 벤더로 구성된 개방형 표준 기반 통합 소프트웨어 스택을 제공하여 개발자가 독점 언어 및 프로그래밍 모델에서 자유로울 수 있도록 지원한다. 현재 엔비디아 GPU, AMD GPU, Arm CPU를 위한 DPC+(데이터 병렬 C++) 및 oneAPI 라이브러리 적용 사례가 있다. oneAPI는 ISV, 운영 체제 벤더, 최종 사용자, 학계에서 광범위하게 채택되고 있다. 주요 업계 리더들은 추가 사용 사례 및 아키텍처를 지원하도록 사양을 발전시키기 위해 노력하고 있다.
또한 컴파일러, 분석기, 디버거, 포팅 도구를 스펙 언어 및 라이브러리를 넘어 추가하는 기본 원API 베이스 툴킷(oneAPI Base Toolkit)을 포함하는 상용 제품을 제공한다.
oneAPI는 아키텍처 전반에서 호환성을 제공하여 개발자 생산성 및 혁신을 향상시키며 인텔 oneAPI 툴킷은 20만 개 이상 설치되었다. oneAPI의 통합 프로그래밍 모델을 기반으로 300개 이상의 애플리케이션이 시장에 제공됐다. 80개 이상의 HPC 및 AI 애플리케이션이 인텔의 oneAPI 툴킷을 사용하는 Xe HPC 마이크로아키텍처에서 작동한다.
5월에 출시된 oneAPI 임시 버전 1.1 사양에는 딥러닝 워크로드 및 고급 레이트레이싱 라이브러리를 위한 새로운 그래프 인터페이스를 추가했으며 연말에 완료될 것으로 예상된다.


한편 폰테 베키오는 오로라(Aurora) 엑사스케일 슈퍼컴퓨터 등에 활용되고 있고 유효성이 입증되었으며 고객에 일부 샘플링을 시작했다. 폰테 베키오는 2022년 HPC와 AI 시장에 출시될 예정이다.
인텔, intel, Xe 고성능컴퓨팅, Xe HPC, Xe-HPC, 폰테베키오, Ponte Vecchio, SoC, 시스템 온 칩, IDM 2.0 전략, EMIB 멀티 다이 인터커넥터 기술, 포베로스 3D 패키징, 활용, 공개










