

서버 | 차세대 암페어(Ampere) 아키텍처 탑재, 엔비디아 데이터센터 GPU A100 발표
엔비디아(www.nvidia.co.kr, CEO 젠슨 황)가 엔비디아 암페어(Ampere) 아키텍처를 기반으로 한 최초의 GPU ‘엔비디아 A100’을 공개했다.
암페어 아키텍처를 기반으로 설계된 A100은 엔비디아 8세대 GPU에서 지원가능한 최대 성능을 제공해 인공지능(AI) 훈련 및 추론을 통합하고, 이전 세대 프로세서 대비 최대 20배까지 성능을 향상시킨다. 또한 A100은 범용 워크로드 가속기로 데이터 분석, 과학 컴퓨팅 및 클라우드 그래픽용으로도 설계됐다.

엔비디아 암페어(Ampere) 아키텍처 A100 GPU
젠슨 황(Jensen Huang) 엔비디아 창립자 겸 CEO는 “클라우드 컴퓨팅과 AI가 데이터센터 구조적 변화를 주도하면서, CPU 전용 서버로 가득했던 데이터센터가 GPU 가속 컴퓨팅 환경으로 전환되고 있다. 엔비디아 A100 GPU는 AI 성능을 20배까지 향상시키며, 데이터 분석부터 훈련 및 추론에 이르는 엔드-투-엔드 머신러닝 가속기다. A100을 통해, 최초로 하나의 플랫폼에서 스케일업(scale-up) 및 스케일아웃(scale-out) 워크로드를 가속화할 수 있게 됐다. 엔비디아 A100은 처리량을 높이는 동시에 데이터센터 비용을 절감할 것”이라고 설명했다.
엔비다아 암페어 GA100 GPU : 7nm 공정과 8192 쿠다 코어, 6144bit 메모리 버스
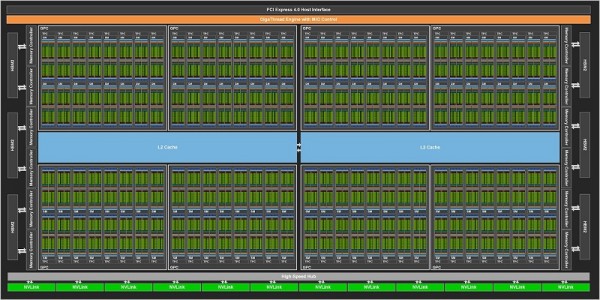
엔비디아 7nm 암페어 기반 GA100 GPU
TSMC의 7nm, N7 공정으로 제조되며 GA100 GPU는 542억개의 트렌지스터, 다이 사이즈는 826 mm^2다. 새로운 스트리밍 멀티프로세서(SM)로 성능을 개선하며 3세대 Tensor 코어로 연산 효율을 높였다. L1 캐시는 볼타(Volta) 아키텍처 대비 1.5배, L2 캐시 용량도 2배로 늘렸다. 3세대 NVLink 도입으로 링크 수는 12개로 볼타 대비 2배, 전체 대역폭도 2배 증가한 600GB/s, PCIe Gen4(PCI Express Gen 4) 인터페이스를 사용하며 CUDA 11을 지원한다.
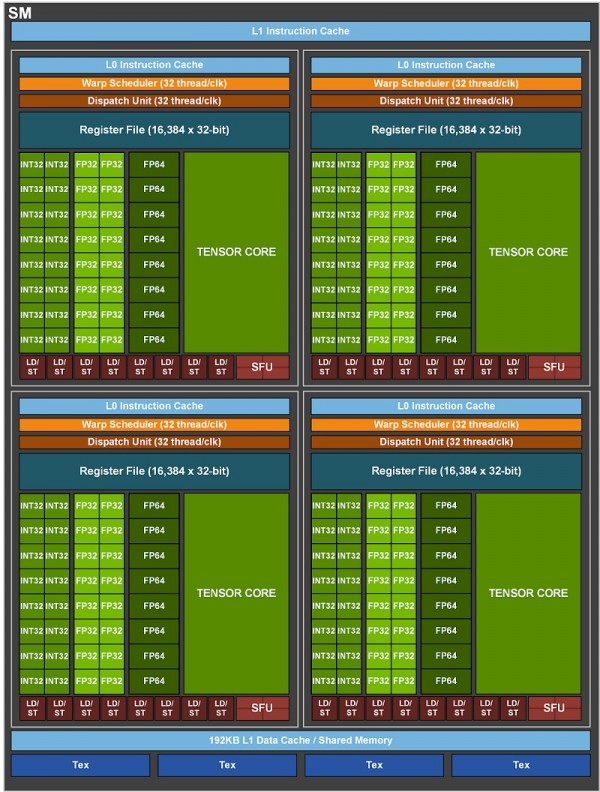
엔비디아 GA100 GPU SM 구조
테슬라 A100(Tesla A100)에 들어간 GA100 GPU는 스펙을 조정해 108 SMs로 6912 쿠다 코어와 5120bit 메모리 버스를 이용한다. 풀스펙 GA100 GPU는 8개의 GPCs, GPC 당 8개의 TPCs, TPC 당 2 SMs, GPC 당 16 SMs, 128 SMs으로 SM당 64개의 FP32 CUDA 코어, 총 8192개의 FP32 CUDA 코어, SM당 4개로 총 512개의 3세대 Tensor 코어, 6 HBM2 스택, 6144bit 메모리 컨트롤러를 탑재한다.
엔비디아 A100 GPU는 다음과 같은 다섯 가지 주요 혁신을 통해 혁신적인 기술 설계를 제공한다.
엔비디아 암페어 아키텍처: A100의 중심에는 540억 개 이상의 트랜지스터를 포함하는 엔비디아 암페어 GPU 아키텍처가 있으며, 이는 세계에서 가장 큰 7-나노미터 프로세서다.
TF32가 탑재된 3세대 텐서 코어(Tensor Core): 이미 업계에서 널리 사용되고 있는 엔비디아의 텐서 코어는 이제 더 유연하고 빠르며 사용하기 쉬워졌다. 코드 변경없이 FP32 정밀도의 최대 20배까지 AI 성능을 높일 수 있는 새로운 AI용 TF32 기능이 추가됐다. 또한 텐서 코어는 현재 FP64를 지원해 HPC 애플리케이션에 대해 이전 세대보다 최대 2.5배 뛰어난 컴퓨팅 성능을 제공한다.
멀티-인스턴스 GPU: 새로운 기술 요소인 MIG는 단일 A100 GPU를 최대 7개의 개별 GPU로 분할하여 여러 규모의 작업에 따라 다양한 수준의 컴퓨팅 기능을 제공함으로써 활용도와 ROI(투자수익율)을 극대화한다.
3세대 엔비디아 NV링크: GPU간의 고속연결을 두 배로 향상시켜 서버에서 효율적인 성능 확장을 제공한다.
구조적 희소성: 새롭고 효율적인 기술로, AI가 가진 본질적으로 희박한 특성을 활용해 성능을 배가시킨다.
이처럼 새로운 기능을 제공하는 엔비디아 A100은 AI 훈련, 추론뿐 아니라 과학 시뮬레이션, 대화형 AI, 추천 시스템, 유전체학, 고성능 데이터 분석, 지진 모델링, 재무 예측을 비롯한 다양하고 까다로운 워크로드에 이상적이다.
엔비디아 암페어 A100 : 볼타(Volta) V100 대비 FP32 6배와 FP16 3배 연산 성능
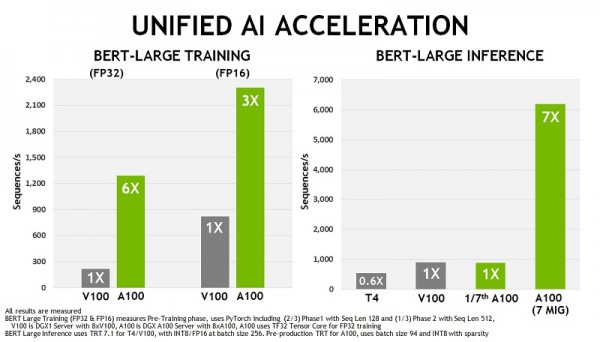
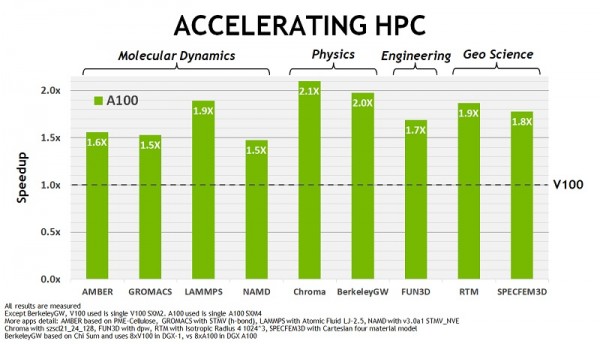
이러한 향상을 통해 엔비디아 A100 GPU는 통합 AI 가속에서 볼타(Volta) V100 GPU 대비 FP32 연산에서 6배(6x), FP16 연산에서 3배(3x), BERT-LARGE INFERENCE에서 7배(7x) 향상됐다. 고성능 컴퓨팅(HPC)을 위한 Molecular Dynamics, Physics, Engineering, Geo Science 등 전반적인 연산 가속에서 1.5배(1.5x)에서 최대 2.1배(2.1x)의 성능을 제공한다.
엔비디아 DGX A100 시스템에 탑재된 엔비디아 A100
새로 발표된 엔비디아 DGX A100 시스템에는 엔비디아 NV링크와 상호 연결된 8개의 엔비디아 A100 GPU가 탑재돼 있다. 이는 엔비디아와 승인된 파트너를 통해 즉시 이용 가능하다.
알리바바 클라우드, AWS, 바이두 클라우드, 구글 클라우드, 마이크로소프트 애저, 오라클, 텐센트 클라우드는 A100 기반 서비스를 제공할 계획이다. 또한, 아토스, 시스코, Dell, 후지쯔, 기가바이트, H3C, HPE, 인스퍼, 레노버, QCT, 슈퍼마이크로를 포함한 세계 유수의 시스템 제조업체들은 다양한 A100 기반 서버를 제공할 계획이다.

엔비디아 HGX A100 서버 플랫폼
엔비디아는 파트너의 서버 개발을 가속화하기 위해 여러 GPU 구성의 통합 베이스보드 형태의 서버 빌딩 블록인 HGX A100을 개발했다. 4개의 GPU가 탑재된 HGX A100은 NV링크와 GPU간의 완전한 상호 연결을 제공한다. 반면, 8개의 GPU가 HGX A100은 엔비디아 NV스위치(NVSwitch™)를 통해 완전한 GPU-투-GPU 대역폭을 제공한다. 새로운 멀티 인스턴스 GPU 아키텍처가 적용된 HGX A100은 각각 엔비디아 T4보다 빠른 56개의 소형 GPU부터, 8개의 GPU로 10페타플롭(PF)의 AI 성능을 제공하는 거대한 서버까지 구성 가능하다.
엔비디아는 또한 애플리케이션 개발자들이 A100의 혁신적인 이점을 활용할 수 있도록 소프트웨어 스택에 대한 몇 가지 업데이트를 발표했다. 여기에는 그래픽, 시뮬레이션, AI를 가속화하는데 사용되는 50개 이상의 쿠다-X(CUDA-X) 라이브러리의 새로운 버전, 쿠다(CUDA) 11, 멀티모달 대화형 AI 서비스 프레임워크인 자비스(Jarvis), 심층 추천 애플리케이션 프레임워크인 멀린(Merlin), 그리고 HPC 개발자가 A100을 위해 코드를 디버깅 및 최적화하도록 돕는 컴파일러, 라이브러리 및 툴을 포함하는 엔비디아 HPC SDK 등이 해당된다.
전세계 기업에서 빠르게 도입하고 있는 엔비디아 A100
A100에 적용된 새로운 엘라스틱 컴퓨팅 기술은 각 작업에 따라 적합한 규모의 컴퓨팅 파워를 제공할 수 있도록 한다. 또한, 멀티-인스턴스 GPU 기능을 사용하면 A100 GPU를 각각 최대 7개의 독립 인스턴스로 분할하여 추론 과제를 수행할 수 있으며, 3세대 엔비디아 NV링크(NVLink ® ) 인터커넥트 기술은 여러 A100 GPU가 대규모의 훈련 과제를 위해 하나의 거대한 GPU로 작동할 수 있게 한다.
A100 GPU는 알리바바 클라우드(Alibaba Cloud), 아마존웹서비스(Amazon Web Services), 아토스(Atos), 바이두 클라우드(Baidu Cloud), 시스코(Cisco), Dell, 후지쯔(Fujitsu), 기가바이트(GIGABYTE), 구글 클라우드(Google Cloud), H3C, HPE, 인스퍼(Inspur), 레노버(Lenovo), 마이크로소프트 애저(Microsoft Azure), 오라클(Oracle), 콴타 클라우드 테크놀로지(Quanta Cloud Technology), 슈퍼마이크로(Supermicro), 텐센트 클라우드(Tencent Cloud) 등을 포함한 세계 유수의 클라우드 서비스 제공업체 및 시스템 구축업체들 제품에 통합될 계획이다.
마이크로소프트는 엔비디아 A100 GPU의 성능을 가장 먼저 확인한 기업으로, 앞으로도 A100의 성능과 확장성의 이점을 활용할 계획이다.
마이크로소프트 부사장 미하일 파라킨(Mikhail Parakhin)은 “마이크로소프트는 최신 엔비디아 GPU를 활용해 세계 최대 언어 모델인 T-NLG(Turing Natural Language Generation)을 훈련시켰다. 애저는 엔비디아의 새로운 A100 GPU를 이용해 더 방대한 AI 모델을 훈련함으로써 언어, 음성, 비전, 멀티 모달리티의 첨단화를 도모할 수 있을 것”이라고 말했다.
도어대시(DoorDash)는 주문형 음식 배달 플랫폼 업체로, 유연한 AI 인프라 구축의 중요성에 주목하고 있다. 도어대시의 머신러닝 엔지니어 게리 렌(Gary Ren)은 “대량의 데이터를 필요로 하는 현대적이고 복잡한 AI 훈련과 추론 워크로드는 엔비디아 A100 GPU와 같은 최첨단 기술을 통해 모델 훈련 시간을 단축하고 머신러닝 개발 프로세스의 속도를 높이는 등 다양한 이점을 얻을 수 있다. 또한, 클라우드 기반 GPU 클러스터를 사용하면 필요에 따라 확장 및 축소할 수 있는 유연성을 확보해 효율성 향상, 운영 간소화, 비용 절감에 도움이 된다”고 말했다.
이 외에도, 국가 연구소, 세계 유수의 고등 교육 및 연구 기관이 A100을 조기에 도입했으며, 차세대 슈퍼컴퓨터에 전력을 공급하기 위해 A100을 사용하고 있다.
HPE의 크레이 샤스타(Cray Shasta)를 기반으로 하는 미국 인디애나 대학교(Indiana University)의 빅 레드(Big Red) 2020 슈퍼컴퓨터는 과학 및 의학 연구, AI, 머신러닝, 데이터 분석 분야의 첨단 연구를 지원한다.
아토스(Atos)에 의해 구축된 JUWELS 부스터 시스템을 갖춘 독일의 율리히 슈퍼컴퓨팅 센터(Jülich Supercomputing Centre)는 극한의 컴퓨팅 파워와 AI 과제를 위해 설계됐다.
독일의 카를스루에공과대학(Karlsruhe Institute of Technology)은 레노버와 함께 호레카(HoreKa) 슈퍼컴퓨터를 구축하고 있으며, 이를 통해 재료과학, 지구시스템과학, 에너지와 이동성 연구를 위한 엔지니어링, 입자, 천체입자물리학 분야에서 훨씬 더 큰 규모의 시뮬레이션을 수행할 수 있게 된다.
독일의 막스 플랑크 컴퓨팅 및 데이터 시설(Max Planck Computing and Data Facility)은 레노버가 구축한 차세대 슈퍼컴퓨터 레이븐(Raven)을 통해 막스 플랑크 연구소에 고성능컴퓨팅(HPC) 애플리케이션의 개발, 최적화, 분석 및 시각화를 지원한다.
로렌스 버클리 국립 연구소(Lawrence Berkeley National Laboratory)에 위치한 미국 에너지국의 국립 에너지 연구 과학 컴퓨팅 센터(National Energy Research Scientific Computing Center)는 HPE의 크레이 샤스타 시스템을 기반으로 차세대 슈퍼컴퓨터 펄뮤터(Perlmutter)를 구축했다. 이를 통해, 첨단 과학연구 지원, 새로운 에너지원 개발, 에너지 효율 개선, 새로운 물질 발견 등을 수행한다.
한편 엔비디아는 현재 전세계 고객을 대상으로 A100을 생산 및 출하하고 있다.
엔비디아, NVIDIA, 차세대, GPU 아키텍처, 암페어, Ampere, GPU, 그래픽 아키텍처, A100, 인공지능, AI, 훈련, 추론 통합, 최대 20배, 성능 향상, 데이터 분석, 과학 컴퓨팅, 클라우드 그래픽용, 설계










