

PC | 엔비디아 파스칼, 최대 3840 쿠다 코어 탑재 및 DP 연산 성능도 개선해
성능과 전력 효율 개선한 파스칼 GP100, 3840 쿠다 코어와 240 텍스처 유닛 탑재
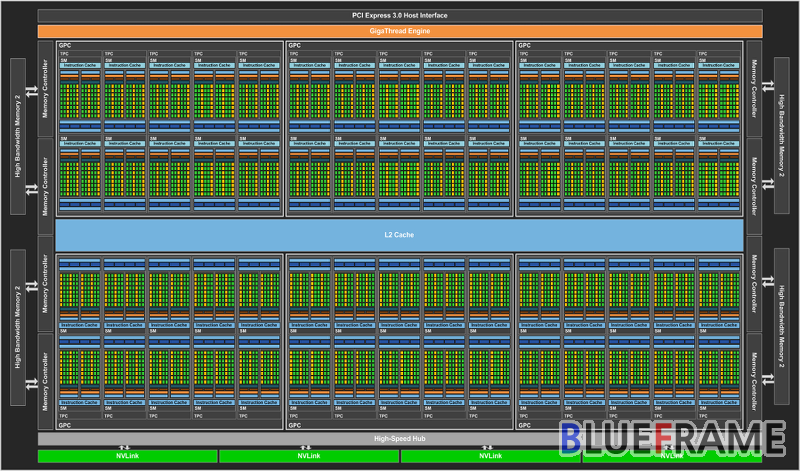
테슬라 P100에 사용된 GP100은 6개의 GPC (Graphics Processing Clusters)로 최대 60 SM, 8개의 512bit 메모리 컨트롤러 (전체 4096bit)를 구성한다.
각 SM은 64 쿠다 코어 (CUDA Cores)와 4개의 텍스처 유닛을 제공해 전체 3840 쿠다 코어와 240 텍스처 유닛을 탑재한다. 테슬라 P100은 28 TPC와 56SM으로 3584 쿠다 코어와 224 텍스처 유닛을 바탕으로 싱글 프리시전 (SP)은 10.6 TFLOPS, 더블 프리시전 (DP)은 5304 GFLOPS (FP64)의 처리 성능을 제공한다.
엔비디아는 케플러 (Kepler)와 맥스웰 (Maxwell)을 거치면서 성능을 끌어올리면서도 전력 효율을 향상해왔다. 파스칼에서도 성능 향상과 전력 효율의 2가지 목표를 지키고 있으며 맥스웰 대비 와트당 성능이 증가했다. TSMC의 16nm FinFET 제조 공정을 도입하면서 더 많은 트랜지스터를 집적해 성능을 높이면서도 전력 효율을 개선할 수 있게 되었다.
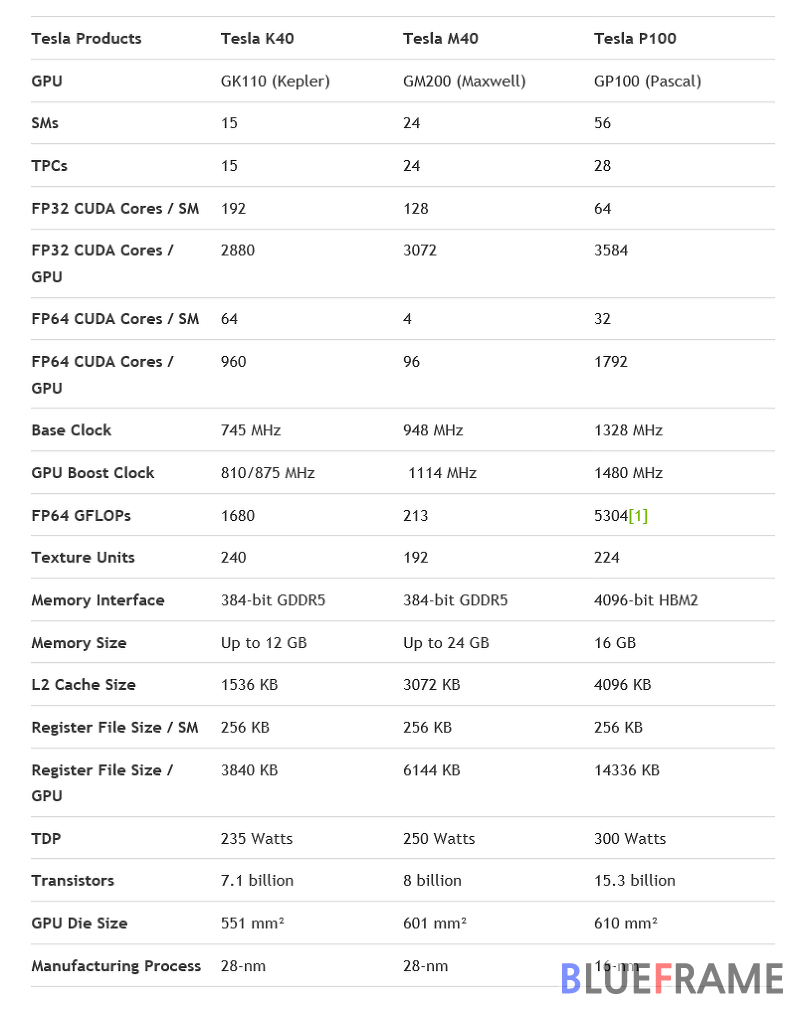
트랜지스터의 수는 케플러 GK110 GPU가 71억개 (7.1Billion), GM200 GPU는 80억개 (8Billion), GP100이 153억개 (15.3Billion)이며 GPU 다이 사이즈는 GK110이 551mm^2, GM200이 601mm^2, GP100이 610mm^2, TDP 스펙은 순서대로 235W, 250W, 300W다.

SM 내부 구조는 케플러나 맥스웰과 차이를 보이나 파스칼은 64 싱글 프리시전 (Single Precision, FP32) 쿠다 코어를 탑재한데 반해 맥스웰은 128 FP32, 케플러는 192 FP32 쿠다 코어를 제공한다. 파스칼 GP100의 SM은 2개의 프로세싱 블럭에 각각 32 싱글 프리시전 (SP) 쿠다 코어를 제공하고 명령 버퍼와 왑 스케쥴러 (Warp Scheduler), 2개의 디스패치 유닛을 제공한다.
맥스웰 SM 대비 GP100의 SM은 절반의 쿠다 코어를 탑재한다. 레지스터 파일 사이즈는 동일하고 유사한 왑과 스레드 블럭을 형성한다. GP100 SM의 레지스터 수는 맥스웰 GM200과 케플러 GK110 SM과 같으나 더 많은 SM을 가진 GP100이기에 전체 레지스터 수는 늘어났다. 이를 통해 GPU는 더 많은 레지스터에 액세스하고 스레드 블록과 왑 접근 등을 통해 이전 세대 대비 더 많은 스레드를 처리할 수 있다.
부동소수점연산 개선, 더블 프리시전 (DP) 비율은 2:1
SM 수가 증가해 GP100 GPU는 전체 공유 메모리도 증가, 2배의 메모리 대역폭 효율을 제공한다. SM 당 높은 비율의 공유 메모리와 레지스터, Warps의 증가는 SM을 더 효율적으로 동작하도록 하는 역할을 해준다.
케플러와 비교해 파스칼의 SM은 간략해진 데이터 패스 구조를 통해 데이터 전송시 더 적은 면적과 적은 전력을 소모하도록 해준다. 향상된 스케쥴링과 부동소수점 처리 효율을 늘렸다. 맥스웰 스케쥴러와 비교해 파스칼 GP100 스케쥴러는 보다 지능적이면서 성능을 높였으며 전력 소모는 더 줄어든 것이 특징이다. 프로세싱 블럭 당 하나의 Warp 스케쥴러는 클럭 당 2개의 Warp 명령어를 디스패치 가능하다.
또 한가지 주목할 것은 더블 프리시전 (DP, Douple Precision) 성능이 케플러 및 맥스웰 대비 향상되었다. 높은 연산 성능을 요구하는 HPC나 기술 컴퓨팅에서 GP100은 높은 DP 성능을 구현한다. GP100의 SM은 32 FP64 유닛을 탑재하며 싱글 프리시전 (SP)와 더블 프리시전 (DP) 비율은 2:1로 케플러 GK100의 3:1, 맥스웰 GM200의 32:1과 비교해 FP64 작업을 효율적으로 처리 가능하다. GP100은 풀 IEEE 754-2008 싱글 프리시전과 더블 프리시전 호환, FMA (Fused Multiply-Add) 등을 지원한다.
보통 DP 연산을 위해서는 더 많은 GPU 전력과 공간을 요구하는데 파스칼 GP100은 16nm FinFET 공정을 기반으로 맥스웰 GM200 대비 크게 증가하지 않은 다이 사이즈에 더 많은 DP 유닛을 넣고 전력 효율까지 향상할 수 있게 되었다.
맥스웰은 네이티브 하드웨어 지원으로 공유 메모리 Atomic 동작을 기존 페르미 (Fremi)나 케플러가 소프트웨어에 의존해 발생했던 오버헤드를 줄였는데 파스칼 GP100은 이에 더해 atomic 처리 향상을 위해 FP64 atomic add 명령값을 전역 메모리에 제공한다. 이를 통해 공유 데이터를 읽고 수정하고 쓰는 일련의 과정을 효율적으로 처리해 병렬 프로그래밍 효율을 향상했다.
15.3Billion, 153억개, 16nm FinFET, 240 텍스처 유닛, 2세대 HBM, 3840 쿠다 코어, 610mm^2, Computex 2016, CUDA Cores, Deep Learning, GeForce GTX 1070, GeForce GTX 1080, GP100, GP104, GPU, HBM2, High Bandwidth Memory 2, HPC, nvidia, NVLink, Pascal, TDP 300W, Tesla P100, 공










