

PC | 인텔 퍼포먼스 하이브리드 아키텍처, 앨더레이크(Alder Lake)
신종코로나바이러스감염증-19(코로나19, COVID-19) 팬데믹으로 비대면 시대의 확장과 백신(Vaccines) 개발, 가상현실(VR, Virtual Reality)과 증강현실(AR, Augmented Reality), 가상화폐(Crypto Currencies), 4차 산업 혁명으로 활발해진 인공지능(AI, Artificial Intelligence), 우주 개발(Space 2.0) 등 새로운 시대의 변화와 이를 위한 컴퓨팅 수요와 첨단 기술의 요구는 더욱 증가하는 추세다.
이에 맞춰 인텔은 한 세대 만에 CPU와 GPU 및 IPU 부분의 대규모 아키텍처 혁신을 공개하는 인텔 아키텍처 데이 2021(Intel Architecture Day 2021)을 8월 19일(현지시간) 개최했다. 이날 인텔이 발표한 새로운 아키텍처와 제품군은 미래 워크로드 및 컴퓨팅 과제 해결을 위한 데이터센터, 엣지 및 클라이언트용 차세대 컴퓨팅 환경을 지원한다.
인텔은 이번 행사에서 새로운 두 개의 x86 코어 아키텍처와 인텔 스레드 디렉터 워크로드 스케줄러를 탑재한 인텔 최초의 퍼포먼스 하이브리드 아키텍처의 앨더레이크, 데이터센터용 차세대 인텔 제온 스케일러블 프로세서인 사파이어 래피즈, 인프라 처리 장치(IPU), 그래픽 아키텍처 제품군으로 Xe HPG와 Xe HPC 아키텍처, 알케미스트와 폰테배키오 시스템-온-칩(SoC) 등 다양한 기술을 발표했다.

라자 코두리 수석 부사장은 “아키텍처는 하드웨어와 소프트웨어의 연금술이다. 특정 엔진에 가장 적합한 트랜지스터를 혼합하고 첨단 패키징으로 연결하며, 고대역폭과 저전력 캐시를 통합한 후, 하나의 패키지 안에 하이브리드 컴퓨팅 클러스터를 위한 고용량, 고대역폭의 메모리와 낮은 레이턴시의 확장 가능한 인터커넥트를 통해 모든 소프트웨어가 원활하게 가속되도록 보장한다. 오늘 공개한 새로운 혁신은 데스크탑에서 데이터센터에 이르는 워크로드가 그 어느 때보다 크고 복잡하며 다양해지고 있으며, 아키텍처가 더 많은컴퓨팅 성능에 대한 수요를 어떻게 충족할 수 있을지를 보여준다.”라며 아키텍처 발전의 중요성을 강조했다.

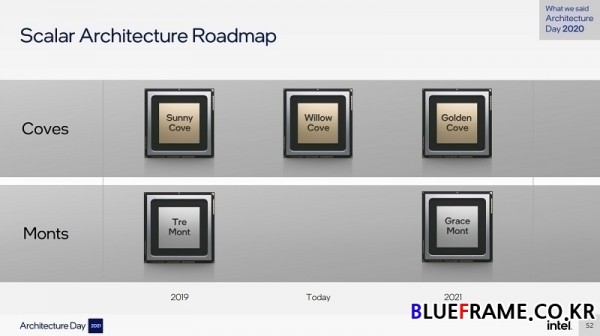
인텔의 아키텍트들은 인텔의 고유하고 풍부한 스칼라(scalar), 벡터(vector), 매트릭스(matrix) 및 스페이셜(spatial) 컴퓨팅 엔진을 결합해 가장 까다로운 워크로드에 비선형적(non-linear) 성능 향상을 제공하는 하이브리드 컴퓨팅 아키텍처를 구축하기 위해 노력하고 있으며 이를 통해 새로운 퍼포먼스 하이브리드 아키텍처 앨더레이크(Alder Lake)가 등장했다.
앨더레이크는 고성능의 코브 시리즈로 2019년 등장해 11세대 코어 프로세서에 사용된 서니 코브(Sunny Cove)와 윌로우 코브(Willow Cov)를 이어 2021년 골든 코브(Golden Cov)로 이어진다. 저전력의 몬트 시리즈는 2019년 등장한 트레 몬트(Tre Mont)에서 2021년 그레이스 몬트(Grace Mont)로 이어지며 앨더레이크는 코브 시리즈와 몬트 시리즈를 조합해 최적의 퍼포먼스 하이브리드 아키텍처를 구성한다.
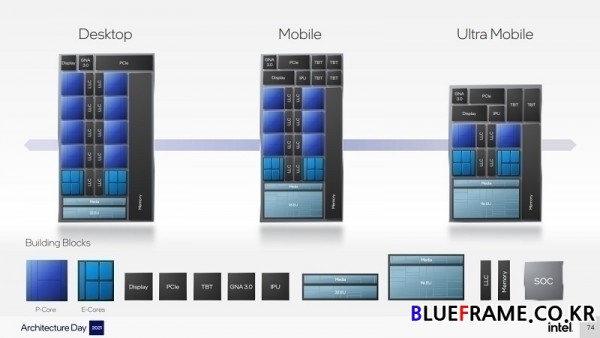
앨더레이크는 퍼포먼스 하이브리드 아키텍처를 기반으로 x86 코어의 코어부와 I/O 다이의 언코어부 등 모듈화된 구조, 확장성이 뛰어난 단일 시스템 온 칩(SoC) 아키텍처를 활용해 게이머들을 위한 울트라 포터블 노트북부터 비즈니스용, 데스크탑에 이르기까지 모든 클라이언트 부문을 지원을 위해 확장성과 향상된 성능을 제공한다.

인텔의 퍼포먼스 하이브리드 아키텍처는 새로운 두 개의 X86 코어로 구성된다. 인텔의 차세대 클라이언트 아키텍처 코드명 앨더레이크(Alder Lake)는 인텔의 첫 퍼포먼스 하이브리드 아키텍처로 모든 워크로드 타입에서 향상된 성능을 위해 퍼포먼스 코어(Performance Core)와 에피션트 코어(Efficient Core)의 2가지 코어 타입을 최초로 통합했다. 앨더레이크는 인텔 7(Intel 7) 공정 기반으로 구축됐으며 최신 DDR5 메모리 및 가장 빠른 IO를 지원한다.
인텔은 무어의 법칙 실현에 중요한 공정과 패키징 기술, 인텔 IDM 2.0 전략으로 공정 및 패키징 혁신 가속화 기사를 통해 소개했듯이 기존 공정은 트랜지스터 게이트 길이를 이용해 구분했으나 현재는 3D 입체 구조 등의 도입으로 게이트 길이와 공정이 일치 하지 않게 됐다. 이에 인텔은 공정 앞에 붙는 나노미터(nm) 단위를 제외하고 반도체 공정 명칭을 새로 정의했다.
인텔 7 (Intel 7)은 기존 명칭이 인핸스드 슈퍼핀(Enhanced SuperFin)으로 10나노(10nm) 공정 기반이다. 핀펫(FinFET) 트랜지스터 최적화를 기반으로 인텔 10나노 슈퍼핀(SuperFin)에 비해 와트당 성능을 약 10%~15% 향상한다. 인텔 7기반 제품은 2021년 선보일 클라이언트 PC용 앨더 레이크(Alder Lake)와 2022년 1분기 생산 예정인 데이터센터용 사파이어 래피즈(Sapphire Rapids) 등이 포함될 예정이다. 이후 인텔은 이후 인텔은 EUV 리소그래피를 전면 도입하는 기존 명칭 7나노미터(7nm) 공정인 인텔 4(Intel 4), 추가적인 핀펫(FinFET) 최적화와 EUV 활용을 높여 면적 개선 뿐만아니라 와트당 약 20% 성능을 향상하는 인텔 3(Intel 3), 옹스트롬(0.1nm) 시대를 여는 리본펫과 파워비아를 활용해 2024년에 생산에 들어갈 것으로 예상되는 인텔 20A(Intel 20A), 2025년 이후 인텔은 인텔 20A를 넘는 인텔 18A를 도입하며 트랜지스터 성능을 다시 한 번 높일 리본펫의 향상과 함께 2025년 초를 목표로 이미 개발 중에 있고 ASML과 긴밀하게 협력 중이다.


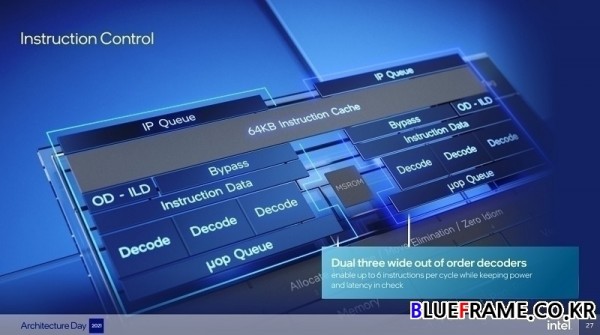
퍼포먼스 하이브리드 아키텍처의 두 개의 X86 코어 중 하나인 에피션트 코어(Efficient-core)는 코드명 그레이스 몬트(Grace mont)로 알려진 인텔의 새로운 에피션트 코어(Efficient core) 마이크로아키텍처로 멀티태스킹을 위한 스루풋 효율성과 확장가능한 멀티스레드 성능을 위해 설계됐다.
에피션트 코어는 인텔의 가장 효율적인 x86 마이크로아키텍처로 공격적인 실리콘 면적을 목표하고 있으며 많은 코어에서 멀티코어 워크로드로 확장 가능하다. 또한 넓은 클럭스피드 범위를 제공한다.
마이크로아키텍처와 설계 노력으로 에피션트 코어는 저전압으로 작동해 전력 소모를 줄이고 헤드룸을 만들어 보다 까다로운 작업 부하에 맞게 주파수를 높이고 성능을 향상한다. 에피션트 코어는 향상된 기술을 활용해 처리 능력을 낭비하지 않고 워크로드 우선순위를 정하며 사이클당 명령(IPC)을 높임으로써 성능을 직접적으로 향상할 수 있다.
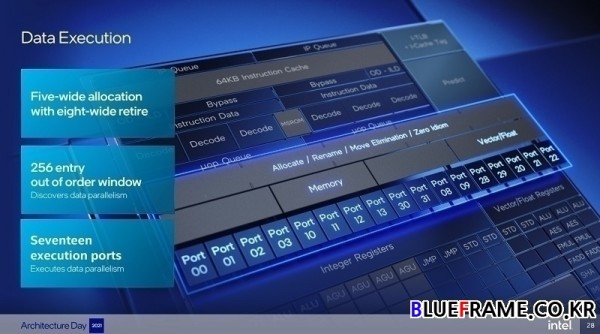
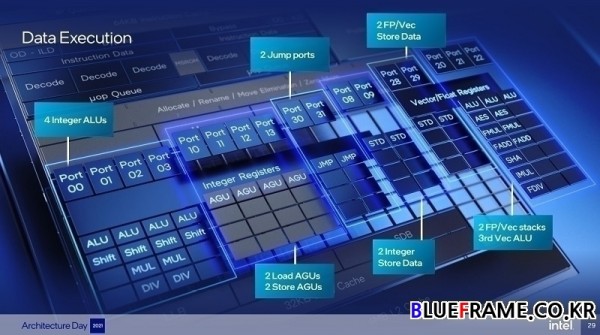


5,000개의 엔트리 분기 타겟 캐시(entry branch target cache)를 통해 보다 정확한 분기 예측 가능, 메모리 서브시스템까지 가지 않고도 유용한 명령어를 가까이 둘 수 있는 64킬로바이트 명령어 캐시, 사전 디코딩 정보를 생성하는 인텔 최초의 온디맨드 방식의 명령어 길이 디코더, 에너지 효율성을 유지하면서 사이클당 최대 6개의 명령어를 디코딩할 수 있는 인텔의 클러스터링된 아웃오브오더 디코더, 폭 넓은 백엔드로 5폭 할당 및 8폭 리타이어, 256개 엔트리 아웃 오브 오더 윈도우 및 17개의 실행 포트, 인텔 제어 흐름 적용 기술 및 인텔 가상화 기술 리디렉션 보호를 지원하는 강력한 보안 기능, AVX ISA의 실행과 새로운 익스텐션으로 정수 AI를 지원한다.

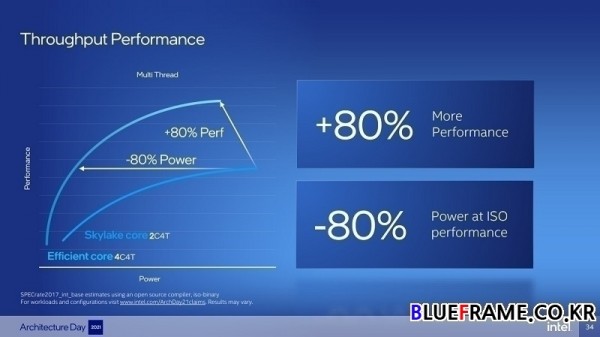
에피션트 코어는 인텔의 CPU 마이크로아키텍처 중 가장 많은 수의 스카이레이크(Skylake)와 비교해 단일 스레드 성능이 향상된다. 동일한 전력에서 40% 더 높은 성능을 달성, 또는 전력의 40% 미만을 사용해 동일한 성능을 제공한다. 4개의 에피션트 코어로 4개의 쓰레드를 활용하는 스카이레이크 코어 2개보다 80% 향상된 스루풋 성능을 제공, 또는 동일한 스루풋 성능을 80% 이하의 전력을 사용해 제공한다.


다른 하나의 X86 코어인 퍼포먼스 코어(Performance-core)는 코드명 골든 코브(Golden Cove)로 알려진 인텔의 새로운 퍼포먼스 코어(Performance core) 마이크로아키텍처로 빠른 속도를 제공하기 위해 설계되었으며 짧은 대기 시간과 단일 쓰레드 애플리케이션 성능 한계를 극복했다.
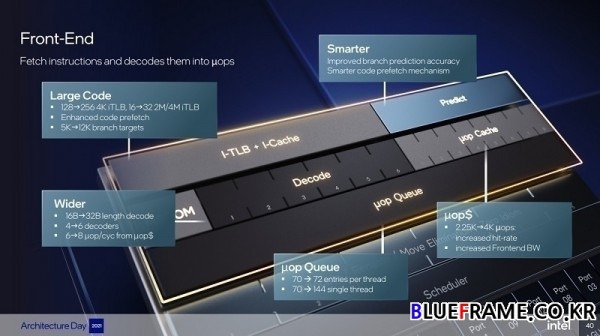
현재 코드 설치 공간의 워크로드가 점점 증가하고 있으며 더 많은 실행 기능에 대한 수요가 증가하고 있다. 데이터 대역폭에 대한 요구사항과 함께 데이터셋의 수도 증가하고 있다. 대용량 코드 애플리케이션을 보다 효과적으로 지원하고 범용 성능에서 확실한 성능 개선을 제공한다. 보다 광범위하고 심층적이며 스마트한 아키텍처를 특징으로 한다.




광범위한 아키텍처는 6개의 디코더 (기존 최대 4개), 8개 마이크로-오퍼레이션 캐시 (기존 최대 6개), 6개의 할당(기존 최대 5개), 12개 실행 포트 (기존 최대 10개) 제공, 심층적인 아키텍처는 대용량 물리적 레지스터 파일, 512개 리-오더 버퍼, 스마트한 아키텍처는 분기 예측 정확도 향상, 유효 L1 지연 시간 감소, L2의 전체 쓰기 예측 대역폭 최적화가 이루어졌다. 퍼포먼스 코어는 인텔이 구축한 CPU 코어 중 최고 성능을 제공하며 짧은 대기 시간을 바탕으로 단일 쓰레드 애플리케이션 성능 한계를 극복했다.
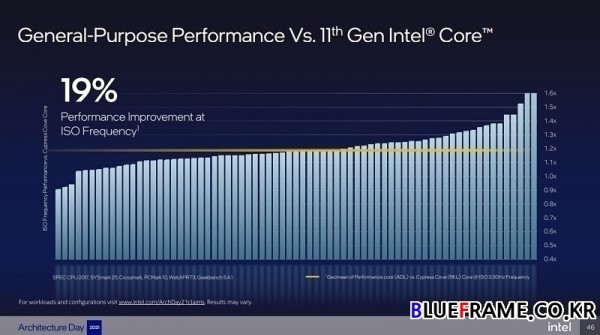
범용 성능은 ISO 클럭스피드에서 현재 11세대 인텔 코어 프로세서 아키텍처(사이프러스 코브, Cypress Cove)에 비해 광범위한 워크로드에서 기하평균(Geomean) 19% 향상, 병렬화 기회를 더 높이고 병렬 실행을 증가한다.


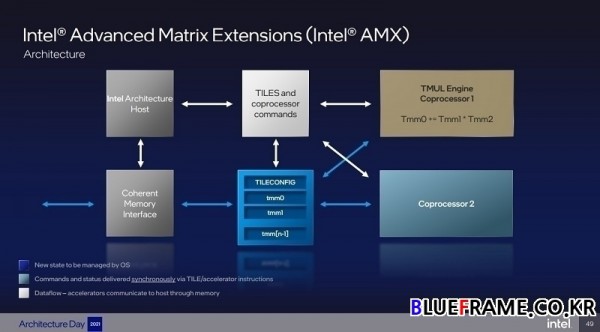
인텔 어드밴스드 매트릭스 익스텐션(Intel Advanced Matrix Extensions)은 차세대 내장 AI 가속화로 딥러닝 추론과 학습 성능을 구현했다. 전용 하드웨어와 매트리스 곱셈 작업을 훨씬 더 빠르게 수행할 수 있는 새로운 인스트럭션 세트 아키텍처 (Instruction Set Architecture)가 포함된다. 대기 시간 단축 및 대규모 데이터, 대규모 코드가 필요한 애플리케이션 지원이 증가했다.

앨더레이크는 최대 16코어 24스레드(16C/ 24T)를 지원한다. 8 퍼포먼스 코어와 8 에피센트 코어로 최대 16코어(16T), 퍼포먼스 코어는 2스레드(2T), 에피센트 코어는 1스레드(1T)로 최대 24스레드(24T)를 제공한다. 메모리는 DDR4-3200과 LP4x-4266을 비롯하여 LP5-5200과 DDR5-4800 지원이 새로 추가됐다.
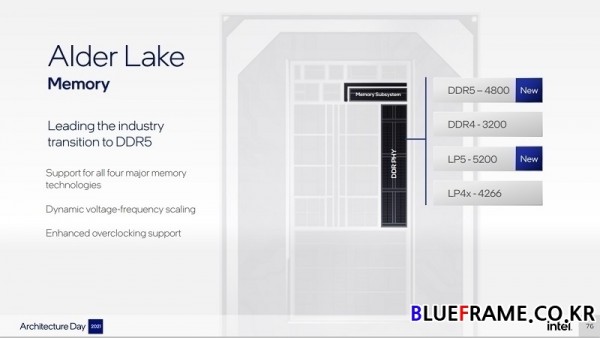
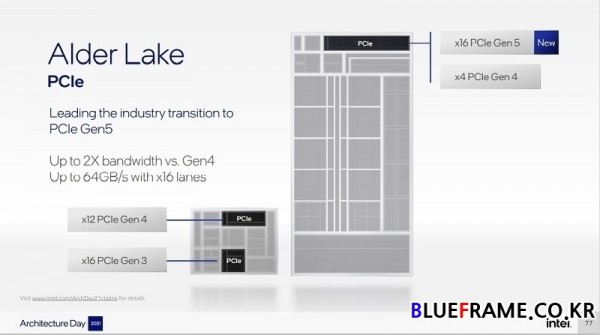
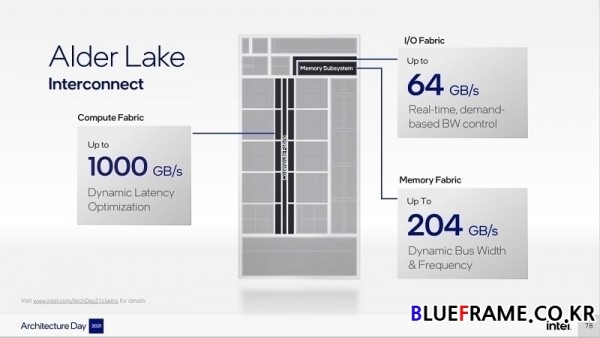
우수한 성능, 전력 효율성, 메모리 및 IO를 갖춘 2칩 소캣 데스크톱의 최고 성능, 이미징과 더 큰 Xe 그래픽 및 썬더볼트 4(Thunderbolt 4) 연결을 추가한 고성능 모바일 BGA 패키지, 최적화된 IO 및 전력 전달을 갖춘 얇고 저전력 및 고밀도의 패키지, 확장성이 뛰어난 아키텍처를 구축하기 위한 과제는 전력의 저하 없이 컴퓨팅 및 IO 에이전트의 엄청난 대역폭 수요를 충족시키는 것이다. 이러한 문제를 해결하기 위해 인텔은 각 실시간 및 수요 기반의 휴리스틱인 세 가지 독립적인 패브릭을 설계했다.
우선 컴퓨트(Compute) 패브릭은 최대 1000GB/s를 지원할 수 있으며 이는 코어 또는 클러스터당 100GB/s다. 마지막 레벨 캐시를 통해 코어와 그래픽을 메모리에 연결한다. 동적 주파수 범위가 높은 것이 특징이며 실제 패브브릭 로드에 따라 레이턴시 vs 대역폭 최적화를 위한 데이터 경로를 동적으로 선택할 수 있다. 활용률(Utilization)을 기반으로 최종 레벨 캐시 정책을 포함(inclusive) 또는 비포함(non-inclusive)으로 동적으로 조정할 수 있다.
IO 패브릭은 최대 64GB/s를 지원하며 다른 타입의 IO를 비롯해 내부 디바이스를 연결하며 디바이스의 정상적인 작동에 지장 없이 데이터 전송을 위해 필요한 수준에 맞춰 패브릭 속도를 선택하면서 속도를 원활하게 변경할 수 있다. 메모리 패브릭은 최대 204Gb/s의 데이터를 제공하고 대역폭과 속도를 동적으로 확장하여 고대역폭, 낮은 레이턴시 또는 낮은 전력에 대한 여러 운영 지점을 지원한다.

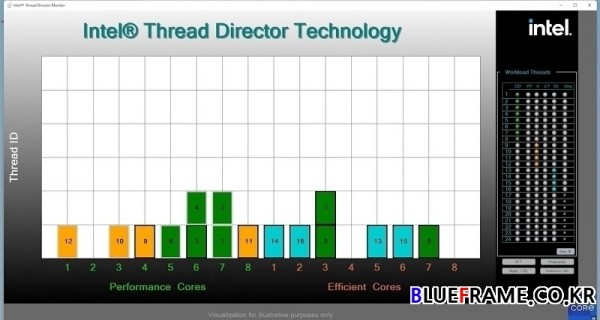
인텔은 퍼포먼스 하이브리드 아키텍처에 인텔 스레드 디렉터(Intel Thread Director)를 추가했다. 인텔 스레드 디렉터는 퍼포먼스 및 에피션트 코어가 운영 체제와 원활하게 작동하도록 향상된 스케줄링 기술을 제공하는 것이다.
하드웨어에 직접 내장된 스레드 디렉터는 코어 상태와 스레드의 명령어 혼합에 대해 낮은 수준의 원격 측정(telemetry)을 제공해 운영 체제가 적시에 올바른 스레드를 배치할 수 있도록 한다. 스레드 디렉터는 단순하고 정적인 규칙 기반 접근 방식이 아닌 실시간 컴퓨팅 요구에 맞춰 스케줄링 결정을 조정할 수 있어 역동적이고 적응력이 뛰어난 것이 특징이다.
기존에 운영 시스템은 포그라운드 및 백그라운드 작업과 같이 사용 가능한 제한된 통계를 바탕으로 의사 결정을 내렸으나 스레드 디렉터는 새로운 차원을 추가한다. 하드웨어 원격 측정을 사용해 더 높은 성능이 필요한 스레드를 해당 시점에 적합한 퍼포먼스 코어로 유도하며 모니터링 명령 혼합, 코어 상태 및 세부적인 수준의 기타 관련 마이크로아키텍처 원격 측정으로 운영 시스템이 보다 지능적인 스케줄링 결정을 내릴 수 있도록 지원한다.
마이크로소프트(Microsoft)와 협력해 윈도우11(Window 11)에서 최상의 성능을 발휘할 수 있도록 인텔 스레드 디렉터 최적화, 개발자가 스레드에 대한 서비스 품질 속성을 명시적으로 지정할 수 있는 파워스로틀링 API(PowerThrottling API) 확장, 스레드가 전력 효율성을 선호하는지 스케줄러에게 알려주는 새로운 EcoQoS 분류 적용(해당 스레드는 에피션트 코어에서 스케줄)한다.

한편 앨더레이크는 2021년 하반기(가을) 등장 예정이다. 퍼포먼스 하이브리드와 인텔 스레드 다이렉트, 인텔 7(Intel 7) 공정, 프로세서는 9W부터 125W 사이, 데스크탑(Desktop) LGA 1700 소켓, 모바일(Mobile) BGA Type3(50 x 25 x 1.3mm), 울트라 모바일(ultra Mobile) BGA Type4 HDI(28.5 x 19 x 1.1mm) 등 다양한 플랫폼과 호환 가능하며 DDR5와 PCIe Gen5, 썬더볼트 4(Thunderbolt 4, 와이파이 6E(Wi-Fi 6E)를 지원한다.
인텔, intel, 퍼포먼스 하이브리드 아키텍처, 인텔 7, Intel 7, 퍼포먼스 코어, Performance Core, 에피센트 코어, Efficient Core, DDR5, PCIe Gen5, PCIE 5.0, x86









