

PC | 3배 이상의 성능 향상, 인텔 10nm 슈퍼핀(SuperFin)
인텔 프로세서는 최근까지 14nm 공정 최적화를 통해 제품을 출시하고 있으나 더 늘어나는 코어와 높아지는 동작 클럭으로 인해 전력 효율과 성능 상승의 한계에 다다르고 있다.
비록 인텔은 2018년 캐논레이크(Cannon Lake)와 컴퓨텍스 2019를 통해 소개한 10세대 코어 프로세서 아이스레이크(Ice Lake) 모바일 프로세서에 10nm 공정 전환을 시도했으나 데스크탑 및 서버 프로세서는 전환이 늦어지면서 코어 수와 성능 경쟁에서 힘겨운 모습이다.
또한 모바일과 네트웍, 디지털, 클라우드(Cloud)와 인공지능(AI) 등에서 엑사스케일(Exascale) 급의 성능과 데이터 증가로 인한 처리와 분석, 보안 등에서도 실시간 처리 등 더 높은 성능의 요구가 이어지고 있다. 하지만 실상은 인텔의 공동 설립자인 고든 무어(Gordon Moore)가 발표한 반도체 집적회로의 성능이 18개월마다 2배로 증가한다는 무어의 법칙(Moore's Law)은 공정 전환과 같은 기술적 한계로 더 이상 큰 영향력을 발휘할 수 없게 되고 있다.
이에 인텔은 8월 13일(현지시간) 아키텍처 데이 2020(Architecture Day 2020)을 열고 새로운 시대의 변화에 맞춰 기술 혁신의 6가지 분야에서의 진전을 소개했다.
6가지 분야의 진전 중 인텔 프로세서 개발에서 발목을 잡고 있는 공전 전환의 열쇠가 될 10nm 슈퍼핀(SuperFin)을 발표했다. 슈퍼핀은 인텔 차세대 타이거 레이크(Tiger Lake)에 적용된다.
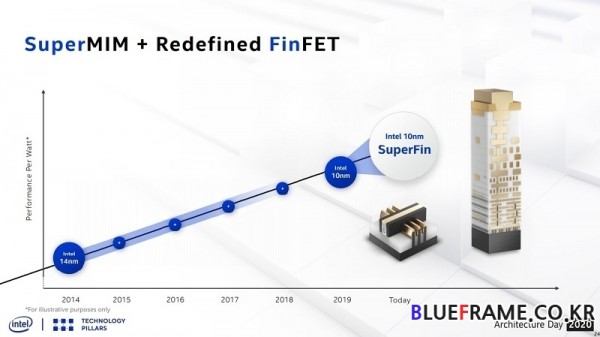
10nm 슈퍼핀은 3세대 핀펫(FinFET)을 적용한 10nm 공정을 다시 개선한 새로운 핀펫 기술이다. 핀펫은 22nm 공정에 3D 트랜지스터를 이용해 트라이게이트(Tri Gate)라 불리는 기술을 도입한 3세대 코어 프로세서 아이비 브릿지(Ivy Bridge)에서 등장한 바 있다.


이 기술은 게이트 길이를 늘려 더 많은 전류가 흐르고 게이트 프로세서 구조를 개선해 더 높은 채널 이동 실현, 소스(Soruce)/ 드레인(Drain)의 결정 구조를 확장해 채널에 흐르는 전류 증가, 메탈 스택에 슈퍼 MIM(Super MIM) 캐패시터 도입과 새로운 High-K 유전체를 사용해 정전용량(물체가 전하를 축적하는 능력)을 5배로 향상하는 것을 골자로 한다. 이를 통해 슈퍼핀은 트랜지스터의 성능을 향상하고 소비전력을 낮출 수 있게 해줘 프로세서 성능과 전력 효율을 한층 향상할 수 있게 된다.
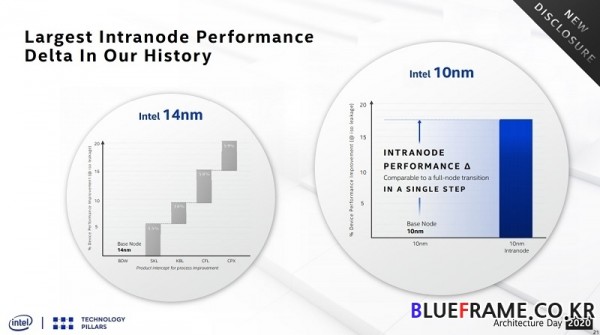
10nm 슈퍼핀은 인텔이 공개한 내용에 따르면 노드 축소 수준의 큰 향상을 보여준다. 이는 기존 공정이 14nm++ 등을 적용하면서 5% 내외로 성능 향상이 더디었다면 슈퍼핀에서는 3배 이상인 최대 17.5% 가량의 성능 향상과 함께 더 높은 클럭을 달성할 수 있다.
인텔의 차세대 모바일 프로세서 코드네임 타이거 레이크는 10nm 슈퍼핀 기술을 기반으로 현재 생산 중이며 연말 홀리데이 시즌에 등장 예정이다.

공정 로드맵에 따르면 2021년에는 슈퍼핀의 확장도 예상되며 2021년 도입될 10nm 슈퍼핀 확장은 데이터 센터의 수요와 칩과 트렌지스터 성능 간의 상호 연결성을 고려해 데이터 센터 제품군에 초점을 맞출 예정이다.


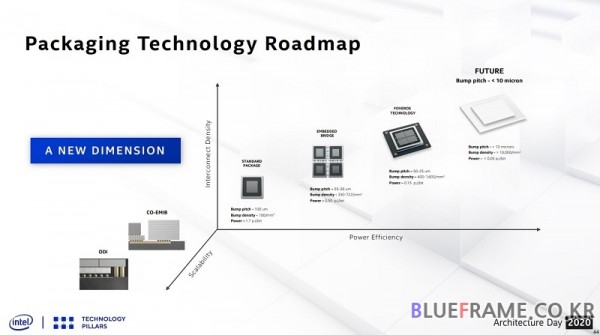
이와 함께 인텔은 새로운 패키지 기술인 하이브리드 본딩(Hybrid bonding)에 대해서도 소개했다. 새로운 패키지 기술을 통해 차세대 프로세서와 칩에 적용해 서로 다른 CPU와 GPU 조합 등 다양한 구성을 성능과 효율, 조합의 다양성을 높일 것으로 예상된다.
하이브리드 본딩(Hybrid bonding)은 대부분의 패키징 기술에 사용되는 전통적인 자기증기압축법 본딩의 대안이다. 하이브리드 본딩은 칩과 칩 사이의 결합이나 10미크론(micron) 또는 그 이하의 범프 피치를 가능하게 해준다. 이를 통해 더 높은 상호연결 밀도와 대역폭, 낮은 전력을 제공한다. 인텔은 2분기 SRAM의 테스트 칩을 테입 아웃(Tape Out)을 진행했다.
하이브리드 본딩(Hybrid bonding) 이전 인텔이 소개한 패키징 기술은 2.5D 기반의 EMIB (Embedded Multi-die Interconnect Bridge)와 3D 포베로스(Forveros), 2.5D와 3D를 조합한 Co-EMIB 등이 알려졌다.

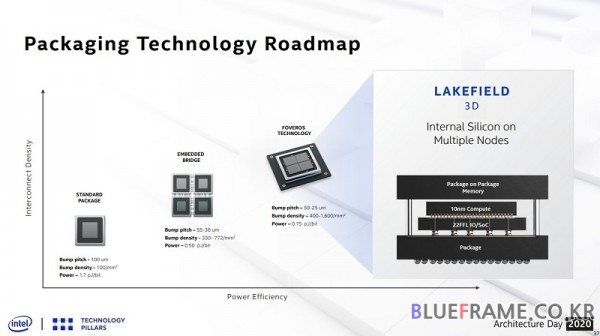
EMIB는 인텔이 발표한 카비레이크-G(KabyLake-G)가 대표적으로 카비레이크-G는 인텔 8세대 코어 프로세서와 AMD 라데온 그래픽스(Radeon Graphics)를 통합했다. 포베로스는 인텔 10세대 코어 프로세서 레이크필드(Lakefield)에 적용된 바 있다.
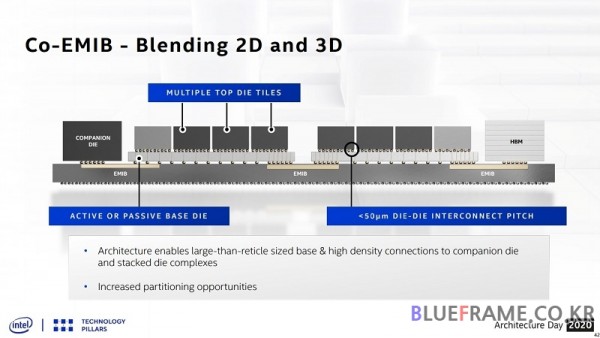

Co-EMIB는 2.5D와 3D를 조합한 기술이며 Co-EMIB는 다중 탑 다이 타일들과 액티브 또는 패시브 베이스 다이로 구성된 칩을 HBM 메모리나 각종 기능의 다이들 등을 연결해 새로운 조합의 프로세서나 칩을 만드는 것이 가능해진다. ODI(Omni-Directional Interconnect)는 최대 성능을 위한 융통성 있는 디자인으로 전력과 직결되거나 고대역 연결 등이 가능하다.
한편 인텔은 설계와 제조가 가능해져 향후 제품에서 상용화 준비를 끝마친 것으로 알려졌다. 이를 통해 CPU 웨이퍼 상단에 SRAM 칩을 탑재한 제품이나 대용량 L4 캐쉬 또는 DRAM을 내장한 CPU도 제작 가능해진다.
인텔, intel, 아키텍처 데이 2020, Architecture Day 2020, 개최, 기술 혁신, 6가지 분야, 진전, 소개, 제조 공정, 공전 전환, 열쇠, 10nm 슈퍼핀, SuerFin, 슈퍼핀, 차세대, CPU, 프로세서, 타이거 레이크, Tiger Lake, 연말, 홀리데이 시즌, 등장 예정









